جمعه, ۷ اردیبهشت, ۱۴۰۳ / 26 April, 2024
مجله ویستا
روشی برای رفع چالش های محتواکاوی وب های فارسی زبان
واژه های كلیدی : آنتولوژی ، نمایه سازی فارسی ، كاوش وب های فارسی ، وب كاوی
مقدمه
اهمیتی كه پدیده وب فارسی بعنوان رسانهای مستقل و مؤثر در دنیای ارتباطات ایرانیان پیدا كرده است ، غیرقابلانكار است. بهنظر میرسد كه اكنون روآوردن برخی از روزنامهنگاران ، پژوهشگران ، دانشجویان ،... به وب فارسی و استفاده منابع خبری ، علمی ،... از مطالب آنها نیز، موجب تقویت نقش رسانهای وب فارسی شدهاست.
لیكن با توجه به ماهیت خاص رسم الخط فارسی كه آن را برای سیستم های رایانه ای نامناسب نموده است ، امروزه مشكلات بسیاری برای دانش پژوهشان و بطور كلی استفاده كنندگان از وب های فارسی زبان نموده است. عدم وجود حروف صدادار در فارسی بصورت یك موجودیت مجزا از یك طرف و وجود حروف یكسان با اشكال متعدد از طرف دیگر ، باعث بروز چالش های جدی در امر نمایه سازی این زبان شده است. بنظر می رسد تلاشهایی لازم است تا زبان زیبای فارسی را با وجود ماهیت عرفانی و شاعرانه آن ، جهت حضور در عرصه الكترونیكی دانش ، آماده نماید.
پیشینه تحقیق و تعارف ابتدایی
محتواكاوی وب(Web Content Mining) ، یكی از سه شاخه وب كاوی است كه در واقع ، كشف اطلاعات مفید از مستندات و داده های ساختیافته و نیمه ساختیافته و غیر ساختیافته وب می باشد. یك شاخه دیگر این مقوله ، ساختاركاوی وب(Web Structure Mining) است كه به كشف مدل پشت زمینه حاكم بر ساختار فرا پیوند های وب می پردازد و هدف آن ، ایجاد اطلاعاتی همچون تشابه یا ارتباط بین سایت های مختلف وب است. شاخه دیگر آن كاربرد كاوی وب می باشد كه سعی می كند از تعاملات كاربربا وب ، اطلاعاتی كسب كند و از آن ها بصورت سابقه ای در مراجعات بعدی كاربر سود ببرد.در زمینه محتواكاوی وب نرم افزارهای خزنده(Crawler) ، به گشت و گذار در اقیانوس وب پرداخته ، اقدام به نمایه سازی واژگان در پایگاه داده خود می نمایند كه مورد استفاده موتورهای كاوش ، در زمان جستجوهای كاربر قرار می گیرد. نمونه بارز این روش ، موتور كاوشگر Google است. .[Chakrabarti,۱۹۹۹]در همین راستا ابزارهایی همچون FASTUS:Finite-State Automaton Text Understanding System ، در خلال این ماموریت به تجزیه و تحلیل متون ، با هدف كشف گروه های مختلف واژگان مانند اسامی ، افعال ، تركیبات وصفی و اضافی ،... می پردازند كه به كشف دانش از محتویات وب كمك می كند. این روش هم اكنون برای زبان های انگلیسی و ژاپنی پیاده سازی شده است وبصورت بالقوه برای دیگر زبان ها قابل استفاده است. [Feiyu,۲۰۰۱]
از طرف دیگر استفاده از آنتولوژی(Ontology) در وب در بهینه سازی كاوش در وب پیشنهاد می گردد. آنتولوژی ، یك فرهنگ واژگان مشترك بر اساس موضوع سایت برای استاندارد سازی ارائه مفاهیم آن جهت قابل تفسیر شدن توسط ماشین ، تعریف می كند. آنتولوژی ، یك جزء كلیدی وب مفهومی(Semantic Web) است. [Heflin,۲۰۰۰]
شخصی كردن وب(Personalization) ، از دیگر روش هاست كه در امر كاوش وب مثمر ثمر است. نمونه این روش در My Yahoo قابل مشاهده است.یكی دیگر از راه های كاوش در مقدار زیاد و غیر ساختیافته اطلاعات وب ، استفاده از پایگاه داده چند لایه ای (MLDB) است. هر لایه از این پایگاه داده ، تعمیم بیشتری از لایه قبلی است. همه لایه ها بجز پایین ترین لایه (كه خود وب است) ، قابل كاوش توسط یك زبان پرس وجو مثل SQL است. [Osmar,۲۰۰۲]
در پیاده سازی روش های ساختاركاوی وب ، از تئوری گراف وب بهره مند خواهیم شد كه به ایجاد دید ارزشمند در الگوریتم های جستجو ، كشف ارتباطات ،... موثر است.در خصوص روش های كاربرد كاوی وب ، ناوبری كاربر در وب توسط مدل های ریاضی ماركو(Markov) ، براساس میزان تجربه كاربر و دارا بودن یا عدم داشتن راهنمای سایت ، تجزیه و تحلیل می گردد. [Velasquez,۲۰۰۳]خصوصیات وب های فارسی از نظر زبان
عدم وجود یك استاندارد و شناور بودن ویژگیهای رسم الخط و مفاهیم در زبان فارسی ، موجب گردیده است تا تقریبا بتعداد صفحات وب فارسی ، سبك و سیاق نگارش این زبان بكار رفته باشد. لیكن خصوصیات مشترك اكثر وبهای فارسی زبان را می توان چنین ارزیابی نمود :
الف) نگارش برخی از وب های فارسی ، زبان غیررسمی یا محاورهای است.
ب) در وبهای فارسی ، بخصوص در متون علمی ، اغلب واژههای بیگانه ، بكرات استفاده میشود كه بعضی از آنها بارسم الخط زبان اصلی نوشته میشوند.
ج) رسمالخط وب های فارسی ، اصولا غیراستاندارد و متغیر است و اغلب در معرض نوآوری است.
ه) نوشتههای وبهای فارسی ، حاوی غلطهای تایپی و نگارشی نسبتاً زیادی است، هرچند كه اغلب وبهای فارسی مهم و پرخواننده، نگارش قابلقبولی دارند.
و) رسمالخط وبهای فارسی، تابع محدودیتهای محیط الكترونیكی و عدم تطبیق آن با الزامات خط فارسی است.]اشرف زاده،۱۳۸۳[ابزارهای جستجو در وب های فارسیدر حال حاضر ابزارهای كاوش مختلفی در ایران ظهور پیدا كرده اند.لیكن ابزارهای جستجویی كه امكان جستجوی اطلاعات به زبان فارسی را در اختیار قرار می دهند ، محدودند. از طرف دیگر ، امكانات و قابلیتهای آن ها برای بازیابی موثر و مناسب اطلاعات متغیر هستند.
برخی از ابزارهای كاوش با امكانات جستجوی فارسی عبارتند از NPiran ، Iranhoo ، IranMehre ، Parseek ، Google و Parseek .بجز سایت NPIran ، دیگر سایتها دارای واسط جستجوی فارسی هستند و بجز Parseek ، هیچیك از ابزارهای موجود كاوش فارسی ، چالش های زبان فارسی را با هدف بهینه سازی كاوش فارسی ، فراروی خود قرار نداده اند و Parseek نیز تنها مشكل كاراكترهای فارسی با یونیكدهای مختلف را حل نموده استدر بین ابزارهای كاوش فوق ، تنها موتور كاوش Google دارای برنامه روبات به منظور شناسایی و نمایه سازی صفحات یا سایتهای وب به زبان فارسی و نمایه سازی خودكار می باشد و قادر است صفحات فارسی را در قالب Unicode شناسایی و در پایگاه خود نمایه كند و سایت Parseek نیز از پایگاه Google برای جستجو و بازیابی اطلاعات استفاده می كند. به تعبیر دیگر، ۴ ابزار كاوش دیگر توسط نمایه سازی انسانی اداره می شوند و از این لحاظ راهنمای موضوعی تلقی می شوند. ابزارهای كاوش دیگر ، راهنمای موضوعی به شمار می آیند و انسان ، فرایند شناسایی، بررسی و نمایه سازی سایتها یا صفحات وب را بر عهده دارد.]كوشا،۱۳۸۱[بنظر می رسد جای یك ابزار كاوش قوی ملی ، تحت نظارت سازمان های انفورماتیكی و انجن های زبان شناسی فارسی ، منطبق با نیازهای اطلاعاتی كاربران اینترنت در ایران وبا در نظر گرفتن چالش های رسم الخط و مفهومی فارسی و مرتفع سازی مشكلات ناشی از آن ها خالی است.مشكلات ومحدودیت های وب كاوی در سایت های فارسی زبان
در دهه های اخیر ، بیشترین اختلاف نظر در باب شیوه املای كلمات فارسی بر سر موضوع جدانویسی یا پیوسته نویسی كلمات مركب بوده است.فرهنگستان زبان و ادب فارسی ، در این باب راه میانه را برگزیده و كوشیده است تا فقط مواردی را كه جدانوشتن و یا پیوسته نوشتن آنها الزامی است ، تحت قاعده و ضابطه درآورد و شیوه نگارش بقیه كلمات مركب را به ذوق و سلیقه نویسندگان واگذار كند.]فرهنگستان،۱۳۸۲[
بعضی چالش های زبان فارسی در رایانه و بخصوص در اینترنت كه باعث تفاوت در نتیجه جستجو در وب یا وب كاوی می شود از قرار زیر است :
الف) تنوع نحوه استفاده از "می" چسبان و غیر چسبان ، مثل كلمات "می تواند" و "میتواند".
ب) تنوع نحوه بكاربردن چسبان و غیر چسبان "ها" ، مثل "آن ها" و "آنها".
ج) بكار بردن بعضی پیشوند ها و پسوند ها ، مثل "همین كه" و "همینكه" ویا "هیچ یك" و "هیچیك" و یا "راه گشا" و "راهگشا".
د) بكاربردن "حمزه" بصورت های مختلف ، مثل "مسؤول" و "مسئول" یا "مسأله" و "مسئله".
ه) استفاده یا عدم استفاده از "ء" ، برای كلمات مختوم به های بیان حركت ، در حالت مضاف ، مثل "خانة مسكونی" و "خانه مسكونی".
و) تنوع استفاده از "ی" در كلمات عربی مختوم به "ا" ، مثل "موسی" و "موسا".
ز) تنوع املایی بعضی كلمات كه همه درست هستند ، مثل "اتاق" و "اطاق".
ح) استفاده از كلمات اروپایی بصورت زبان اصلی یا ترجمه فارسی بخصوص در متون علمی ، مثل "Update" و "بروزآوری".
ط) استفاده یا عدم استفاده از جمع مكسر برای بعضی كلمات.
ی) تبدیل كلمات اروپایی به رسم الخط فارسی با همان تلفظ اصلی ، مثل "Source" و "سورس".
ك) استفاده از "ا" و "آ" بجای هم ، مثل "فرایند" و "فرآیند".
ل) استفاده یا عدم استفاده از اعراب برای كلمات .
بعبارت دیگر ، یك كاربر ممكن است در جستجوی خود در وب ، كلمه كلیدی خاصی را بكار برد ، لیكن در صفحات وب چنین كلمه ای بكار نرفته باشد و با توجه به مواردی كه در مورد تنوع كاربری كلمات ، بحث شد ،كلمه مشابهی ثبت شده باشد. بنابراین بسیاری از صفحات وب مطلوب كاربر ، در مجموعه بازیابی شده ، وجود نداشته باشد.
روش هایی برای بهبود كاوش وب های فارسی
الف) انتخاب مناسب سرعنوان های موضوعی در وب های فارسی
پیدا كردن اصول و معیارهای موضوع سازی ذهنی و فرایندی كه در ذهن كاوشگران اطلاعات در هنگام بیان موضوعات ، برای پاسخ یابی ماشینی ، روی می دهد یك فرایند پیچیده ، مهم و تاثیرگذار در جریان تهیه سرعنوان های موضوعی است. از طرفی تركیب بندی عبارات كاوش با یك زبان مشترك بین انسان و ماشین ، از جمله مسایلی است كه همیشه متخصصان بانك های اطلاعاتی و كاوشگران اطلاعات را دچار مشكل می سازد. بهمین دلیل و با توجه به ساختار بانك های اطلاعاتی ، حوزه موضوعی كاوش ، میزان آگاهی های عمومی كاوشگر ، زبان رایج تخصصی میان ورزیدگان یك رشته خاص موضوعی ، مسائل و مشكلات زبانی ، ساختار اصطلاحنامه بكار گرفته شده در بانك اطلاعاتی و … است كه راهبردهای كاوش ، طراحی و اجرا می شوند. در این مسیر ، سرعنوان های موضوعی ، نقش عمده ای را دارا هستند. حل این مسائل می تواند به پیدا كردن راه حل های موثری برای سرعنوان های موضوعی بیانجامد.]بیگلو،۱۳۸۲[
ب) استمداد از علم اصطلاح شناسی(Terminology) در نمایه سازی ماشینی
توجه به اصطلاحات و اصطلاح سازی نیز با توجه به ضرورت روزآمد بودن واژگان علمی و تخصصی و لزوم كنترل ورود اصطلاحات بیگانه امری است كه ما را ناگزیر به استمداد از علم اصطلاح شناسی وامی دارد.در این خصوص "حسینی" پژوهشی ارائه كرده است كه بجهت اشاره به تمهیدات وی در خصوص تشكیل ویا بهینه سازی اصطلاحنامه ای مناسب برای نمایه سازی ماشینی ، شمه ای از آن در ادامه مشروح می باشد :
الف) كنترل مترادف ها و شبه مترادف ها بصورت ارجاع مترادف های غیر مرجح به اصطلاح مرجح.
ب) هدایت كاوشگر از مفاهیم و اصطلاحات اخص به اعم یعنی نزدیك ترین اصطلاح.
ج) با ارائه روابط ساختاری مفاهیم اعم از سلسله مراتبی یا غیر سلسله مراتبی ، جامعیت حاصل می گردد و كاوش را با ارائه طبقه های دارای ارتباط بسیار نزدیك توسعه می دهد. از این طریق مانعیت نیز با پیشنهاد اصطلاحات اخص ، بهبود می یابد.
د) نظارت بر شكل دستوری ، املایی ، جمع و مفرد و اختصارات و شكل مركب اصطلاح.
ه) گزینش بین دو یا چند مترادف موجود برای بیان یك مفهوم.
و) تصمیم گیری در خصوص پذیرش و نحوه برخورد با انواع خاصی از اصطلاحات نظیر "واژه های قرضی"(Loan Words) ، "واژه های عامیانه"(Slang Words) ، اسامی تجاری و اسامی خاص.
ز) محدود كردن معنی یك اصطلاح كه در یك فرهنگ ممكن است با توضیحات گوناگون همراه باشد.
توصیه های اضافی در خصوص تشكیل اصطلاحنامه بشرح زیر است :
الف) واژه های قرضی :
واژه هایی كه از زبانهای دیگر قرض گرفته شده اند و در زبان قرض گیرنده تثبیت شده اند. چنانكه ترجمه این اصطلاحات وجود داشته باشد ولی بطور رایج مورد استفاده قرار نگیرد با صاطلاح ترجمه شده باید بصورت اصطلاح نامرجح برخورد كرد.
ب) نو واژه ها(Neologisms) ، اصطلاحات عامیانه و زبان حرفه ای :
چنانچه جایگزینی كه بطور گسترده توسط كاربران مورد استفاده قرار گیرد ، وجود نداشته باشد ، نو واژه ، اصطلاح عامیانه یا حرفه ای ، بعنوان توصیفگر پذیرفته می شوند.
ج) اسامی عامیانه و اسامی تجاری :
توصیه می شود ، در جایی كه اسم عامیانه معادلی وجود دارد ، باید از آن بجای اسم تجاری استفاده كرد.
د) اسامی مشهور و اسامی علمی :
انتخاب بین ایندو بر اساس احتمال بیشتر استفاده كاربران می باشد.
ه) اسامی مكان ها :
در جایی كه برای یك كشور یا منطقه جغرافیایی درون یك جامعه تك زبانی ، بیش از یك اسم ، انتخاب می گردد ، باید اسمی را بعنوان اصطلاح مرجح تعیین كرد كه نزد كاربران ، آشناتر است.
و) اسامی خاص موسسات ، افراد و...
میزان نیاز دستیابی به اسامی خاص بر اساس حوزه عملكرد اصطلاحنامه ، گنجاندن اسامی را در اصطلاحنامه اصلی تعیین می كند.
ز) همنام ها و هم آوا ها :
منظور ، كلماتی هستند كه دارای املاء یكسان و معانی متفاوت یا دارای آوای یكسان و معانی متفاوت می باشند. در چنین مواردی روش معمول ابهام زدایی ، اضافه كردن توضیحگر است كه داخل پرانتز قرار می گیرد.
ح) مترادف ها :
انتخاب مترادف ها باید بر اساس نیاز های كاربران باشد كه از نقطه نظر رواج و تخصص ، صورت می گیرد.
ط) شبه مترادف ها :
پذیرش شبه مترادف ها ، از حوزه موضوعی زیر پوشش اصطلاحنامه ، متاثر است. برای مثال "افراد با استعداد" و "تیزهوشان". شبه مترادف ها ممكن است شامل متضاد ها هم باشند مثل "سوادآموزی" و "بیسوادی".]حسینی،۱۳۸۳[
ج) تعریف یك استاندارد برای مفاهیم و رسم الخط فارسی در وب
همانطور كه گفته شد ، یك تفاوت زبان فارسی با زبان انگلیسی (و زبان های هم ارز) ، تنوع املایی یا رسم الخطی كلمات آن است. بعبارت دیگر ، در زبان انگلیسی ، تنوع در مفهوم كلمات وجود دارد. یعنی برای بعضی مفاهیم ، ممكن است كلمات متنوعی استفاده شود. برای مثال كلمات "Hello" و "Hi" كه دارای مفهوم یكسانی هستند. لیكن در فارسی ، علاوه بر وجود كلمات متنوع برای مفاهیم یكسان ، مثل "كامپیوتر" و "رایانه" ، تنوع در رسم الخط یك كلمه نیز فراوان بچشم می خورد. بعبارت دیگر ، در حالی كه شما بدنبال صفحات محتوی كلمه "امپراتور" می گردید ، كلیه صفحات محتوی كلمه "امپراطور" را از دست می دهید.بنظر می رسد ، در تشكیل صفحات وب فارسی ، جای یك استاندارد حاكم بر عملكرد تالیف نویسندگان وب ، خالی است. استانداردی كه انتخاب بعضی كلمات دارای چندین رسم الخط و حتی انتخاب بعضی كلمات كه بر مفاهیم متنوعی دلالت دارند را منحصر بفرد نماید و مولفان را از طرفی ترغیب به انتخاب گونه زبانی مناسب، برای تضمین كیفیت ارتباط و انتقال مؤثر پیام و از طرف دیگر موظف به حفظ سلامت زبان و رعایت استانداردهای آن بهعنوان یك وظیفه رسانهای نماید.
ایجاد و گسترش چنین استانداردی بعهده "فرهنگستان زبان و ادب فارسی" و با هماهنگی انجمن ها و شوراهای علمی یا صنفی انفورماتیك در ایران است. تعویق در تنظیم این استاندارد ، با توجه به رشد روز افزون وب های فارسی زبان ، هزینه های جبران ناپذیری در بر خواهد داشت
د) استفاده از مفرد و جمع در نمایه سازی
استفاده از اسامی جنس ، نحوه جمع بستن كلمات بصورت باقاعده با بدون قاعده (جمع های مكسر) معضلی است كه در نمایه سازی واژگان فارسی معمولا بسیاری از صفحات وب را شامل نمی شود. در این خصوص "سمایی" در مقاله خود قواعدی را برای نمایه سازی واژه های مفرد و جمع ارائه داده است كه ذكر آن ها خالی از لطف نیست :
الف) از آنجا كه كلیدواژهها در زبان تخصصی بكار میروند و در بین اهل فن رایج و جاریاند، گاه اتفاق میافتد كه صورت جمع مرسوم باشد. در این حالت بهتر است كه از صورت جمع استفاده شود. نظیر تركیب "آثار باستانی". نكتهای كه در این باره ذكركردنی است، شیوة جمع بستن اسامی در این موارد است. بدین معنا كه گاهی نوع پسوند جمع یا شیوة جمع بستن باعث میشود كه اصطلاح به دست آمده، با سنت رایج در حوزه تخصصی منطبق نباشد. مثلاً چنانچه لفظ اثر با "ها" جمع بسته و تركیب "اثرهای باستانی" ساخته شود، با اصطلاح رایج اهل فن متفاوت خواهد بود.بعلاوه این كه در برخی موارد، شیوة جمع بستن باعث تفاوت در معنا میشود."اثرها" در برخی بافتها معادل "آثار" نیست. "آثار" در تركیب با "باستانی"» شامل خرابهها و بناها و اشیای به جا مانده از زمان قدیم میشود، در حالی كه از لفظ "اثرها" بیشتر معنای ردّ و نشان تداعی میشود.
ب) گاهی صورت مفرد كلمه، معنایی متفاوت از معنای جمع دارد. این مسئله اغلب در كلمات عربی مصطلح در فارسی وجود دارد. تركیب "مصالح راهسازی" از این دست است. "مصالح" بمعنای مواد لازم برای ساختن بنا است، در حالی كه معنای صورت مفرد آن یعنی "مصلحت" ــ به نقل از فرهنگ معین ــ از این قرار است: "آنچه كه صلاح و سود شخص یا گروهی در آن باشد".
ج) در مواردی ، با این كه صورت مفرد و جمع كلمه، معنایی مشترك دارند استعمال صورت مفرد در زبان رایج نیست. به همین علت تركیبهایی نظیر "منسوجات نظامی" "الیاف كربنی" را نمیتوان بشكل مفرد آورد و به جای منسوجات لفظ "منسوج" و به جای الیاف لفظ "لیف" را قرار داد.
د) در برخی واژهها، صورت جمع توسّع معنی پیدا كرده و از این طریق، ارتباط صورت جمع و مفرد ضعیف شده است. در واژهای نظیر "مهمّات" این اتفاق رخ داده و ارتباط "مهمات" با "مهم" از این دست است.
ه) بعضی تركیبها نظیر "ماشینآلات" وجود دارند كه نه تنها نمیتوان قسمت جمع آنها را به شكل مفرد آورد ، بلكه در مجموع، یك واحد نحوی ایجاد میكنند كه از لحاظ معنایی تجزیهناپذیر است.
و) گاهی هم اتفاق میافتد كه جمع اسم با قاعده فارسی، در زبان مصطلح نیست و جمع عربی آن رایج است. بدیهی است كه در این حالت چنانچه اسم مذكور، كلیدواژه شود یا در تركیبی به كار رود و نتوان از صورت مفرد آن استفاده كرد، باید شكل جمع عربی آن را به كار برد. در تركیب "اجزای پل" نمیتوان به جای "اجزا" لفظ "جزءها" را به كار برد.
ز) برای جمع بستن اسامی لاتین استفاده از پسوند "ها" مرجح است: "كرباماتها".]سمایی،۱۳۸۲[
ه) استفادهازیك واسطكاوش فارسی برای رفع چالشهای رسمالخط و مفهومی
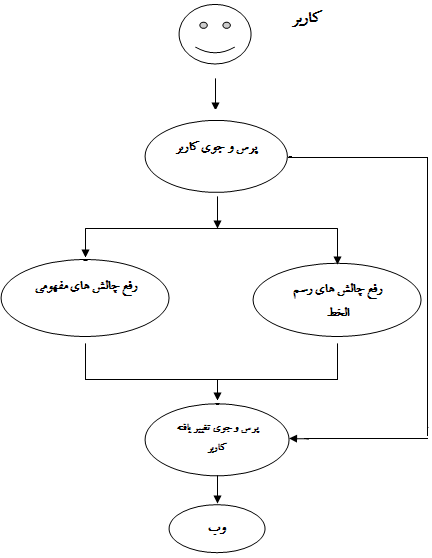
استاندارد سازی رسم الخط فارسی در رایانه ها ، ممكن است در ابتدای تولید اولین صفحات وب فارسی بسیار مفیدتر بنظر رسد ، لیكن در حال حاضر ، با وجود تعداد بسیار زیادی صفحات وب فارسی كه در هر حال با عدم نظارت یك استاندارد ، تولید شده اند ، چندان مثمر ثمر واقع نمی شود. اگر چه ایجاد آن برای تولید صفحات وب فارسی آتی ، لازم است. بعبارت دیگر ، جهت انجام عملیات وب كاوی در صفحات وب فارسی كنونی ، بایستی روشی ابداع كرد تا با توجه به چالش های بحث شده ، نتایج مطلوبی از وب كاوی در آنها بدست آید.
با توجه به بحث های قبل ، می توان دریافت كه در كاوش های وب ، پارامترهایی كه نتایج جستجو را برای كاربر مطلوب جلوه می دهد ، از قرار زیر است :
الف) جامعیت نتایج(Recall) :
منظور از جامعیت نتایج ، اینست كه كلیه صفحات وبی كه بر اساس كلمه كلیدی ، مطلوب كاربر محسوب می گردد ، نمایش داده شود. بعبارت هیچ صفحه مطلوبی از قلم نیافتد.
ب) مانعیت نتایج :منظور از مانعیت نتایج اینست كه صفحات وبی اضافه بر نتایج جستجوی مطلوب كاربر ارائه نشود ، كه بعلت حجم زیاد نتایج ، باعث سردرگمی كاربر گردد.
ج) تناسب نتایج(Precision) :میزان مطلوب بودن نتایج نسبت به مورد جستجو است كه باید حداكثر باشد.
د)سرعت بازیابی:نكته مهم دیگر در كاوش ، زمان صرف شده برای جستجو است كه بایستی حداقل باشد. این پارامتر ، به میزان ترافیك شبكه ، سرعت خدمت دهنده ها ، سرعت پایگاه داده نمایه شده و موارد سخت افزاری وابسته است.لیكن جامعیت ، مانعیت و تناسب نتایج ، می توانند تحت تاثیر زبان استفاده شده در نگارش محتوای صفحات ، تغییر نمایند. بخصوص موقعی كه زبان مورد استفاده ، زبانی همچون فارسی با چالش های رسم الخط فراوان در گستره امور رایانه ای است و بشدت مستعد نتایج بی اعتبار و نامناسب می باشد. بعنوان مثال كاربر جوینده اطلاعات در مورد "امپراتوری های قدیم" از دیدن صفحات وب حاوی كلمه "امپراطور" در نتایج جستجوی خود ، محروم است.لذا در خصوص ارتقاء كیفیت نتایج كاوش در وب های فارسی زبان ، جای راهكارهایی كه پارامترهای مذكور را تقویت نماید خالیست. از این رو ، بر آن شدیم تا با ایجاد یك عامل هوشمند ، نتایج جستجوها را بهینه كنیم. اینكار را با اضافه كردن یك واسط هوشمند به موتورهای كاوش یا خزنده ها انجام دادیم. ین واسط در واقع نقش یك پردازشگر پرس و جو(Query Processing) را ایفاء می كند.این عامل از دو قسمت تشكیل شده است. یك قسمت به مرتفع سازی معضلات رسم الخط و بهبود بعد جامعیت نتایج كاوش و قسمت دیگر به رفع مشكلات مفهومی و بهینه سازی تناسب و مانعیت نتایج كاوش می پردازد.واسط فارسی برای بهبود جامعیت كاوش این قسمت از عامل ، از یك پایگاه داده تشكیل شده است كه حاوی چندین كلمه معادل بعضی كلمات خاص كه در چالش ها ذكر گردید ، می باشد. این تناظر ، می تواند مربوط به معادل های رسم الخط ، معادل های مفهومی یا معادل هایی به زبان های غیر فارسی باشد. بدین صورت كه با عبور دادن كلمات مورد كاوش از این واسط و یا با رجوع به این پایگاه داده ، عملا یك كاوش بر اساس یك كلمه كلیدی خاص ، منجر به چند كاوش برای كلمات معادل آن كلمه كلیدی خاص می گردد. با این ترفند ، صفحات حاوی كلمات معادل ، از دست نمی رود و پارامتر جامعیت را تقویت می نماید.
واسط فارسی برای بهبود مانعیت وتناسب كاوش
همانطور كه در فصل قبل تشریح گردید ، آنتولوژی می تواند ، با ایجاد ساختار مفهومی مناسب ، بر حسب موضوع اصلی سایت وب (مثل وب خدماتی ، تولیدی ، علمی ،...) كاوش ماشینی را تسهیل كند. چرا كه با روشن بودن نوع وب از نظر موضوع وساختار پیوندی آن (شكل گراف وب) با توجه به آنتولوژی استانداردی كه برای كاوشگر نیز شناخته شده است ، بطور بهینه ای می توان عملیات كاوش را بثمر رسانید. بعبارت دیگر اگر كاربری در مورد "پایان نامه های تحصیلی" جستجو كند ، موتور كاوشگر ، با اطلاع از نوع سایت های دانشگاهی ، دقیقا با مراجعه به پیوند های مربوطه (مثل "پژوهش ها" ، "پایان نامه ها" ،...) در سایت های مربوطه ، نتایج بهینه ای را در اندك زمانی فراهم نماید.
با تعریف یك گراف بدون جهت مفهومی (گراف آنتولوژی) محتوی واژه های فارسی و ارتباط بین آنها می توان گامی در جهت بهبود نتایج كاوش از نظر مانعیت ، برداشت. گراف عمومی ما شامل اجزاء زیر است :
الف) گره ها كه واژه متناظر با آن ها ، دلالت بر یك موجودیت فیزیكی یا مفهومی دارد. مثل ایران ، میز ، كشور ، حیوان ، درخت ، اسب ،... هریك از این گره ها ، با یك كد مشخصه گره ، یك واژه گویای موجودیت آن و یك عدد نشان دهنده فاصله آن گره تا ریشه است.
ب ) پیوند بین گره ها : شامل پیوند های بین آنهاست كه هر یك معرف رابطه مفهومی بین واژه هاست. هر پیوند از نظر ساختار ، حاوی یك كد مشخصه پیوند ، كد مشخصه گره شروع و كد مشخصه گره پایان می باشد.زمانی كه كاربر ، كاوش خود را در مورد كلمه خاصی آغاز می كند ، معمولا درابتدا نتایج بسیار زیادی دریافت می كند كه بعلت عدم اعمال محدودیت روی كلمه مورد كاوش وی می باشد. واسط هوشمند ، در مراحل بعدی كاوش ، با محدود كردن دامنه جستجو با توجه به كلمات مورد نظر كاربر و بر اساس آنتولوژی موجود ، سعی در فیلتر كردن نتایج حاصل از كاوش دارد. واسط مفهومی ما با در نظر گرفتن كلمات استفاده شده در كاوش های قبلی كاربر ، اقدام به یافتن مسیری در گراف عمومی مذكور ، بین واژه های بكار رفته می نماید.اگر در گراف مذكور ، مسیری با طول قابل قبول یافت شد ، واسط ، گره های موجود در بین این مسیر را شناسایی نموده ، گره با كمترین فاصله تا ریشه را ، مبنایی برای فیلتر كردن سایتهای وب كاوش شده قرار میدهد واز ارائه سایتهای دیگر به كاربر ،كه موضوع آنها با واژه گره اصلی همخوانی ندارد ، اجتناب می ورزد و بدین طریق به مانعیت و تناسب نتایج حاصل از كاوش بهبود می بخشد.برای مثال اگر كاربر كاوش خود را با واژه "آنتولوژی" شروع نموده و در مراحل بعدی جستجوی خود ، واژه های "ساختار معنایی" ، "وب معنایی" و... را مورد كاوش قرار دهد ، واسط فارسی اقدام به یافتن مسیری از واژه "آنتولوژی" تا واژه "وب معنایی" می نماید و در فاصله این مسیر به گره اصلی "رایانه" می رسد. از این پس ، واسط ، نتایج حاصل از كاوش كاربر را به صفحاتی با موضوع اصلی "رایانه" محدود می كند و از ارائه صفحاتی با موضوع اصلی "فلسفه" خودداری می ورزد.
معماری
این عامل هوشمند ، در خصوص هر یك از چالش های رسم الخط زبان فارسی رایانه ای ، رفتار متفاوتی از خود نشان می دهد. این رفتارها بقرار زیر است :
الف) تنوع نحوه استفاده از "می" ، "ها" ، پیشوند ها و پسوند ها :
همانطور كه قبلا توضیح داده شد ، موارد فوق بطور چسبیده یا جدا از كلمه بكار برده می شود. لذا جهت رفع چنین مشكلی ، می توان در واسط هوشمند ، با حذف كلیه فواصل خالی(Blanks) موجود در عبارت مورد كاوش ، اقدام به جستجو بر اساس دنباله ای از حروف همان عبارت ، بدون هیچگونه فاصله خالی نمود.
ب) بكاربردن "حمزه" بصورت های مختلف :
جهت حل مشكل فوق ، در عمل هوشمند مورد بحث ، فرآیندی ایجاد می گردد ، كه طی آن ، اگر عبارت مورد كاوش حاوی صور مختلف "حمزه" باشد ، عملا كاوش ، به چندین جستجو برای كلمات مشابه ، با حالت های مختلف "حمزه" تبدیل می شود. بعبارت دیگر كاوش كلمه "مسئله " به كاوش برای كلمات "مسئله" و "مسأله" منجر می شود. می توان با جایگزینی "ی" بجای "ء" نیز دامنه كاوش را وسیع تر نمود ، مثل "رئیس" و "رییس".
ج) استفاده یا عدم استفاده از "ء" در تركیب های اضافی یا وصفی :
جهت رفع این مشكل ، در صورت استفاده كاربر از "ء" در عبارت مورد كاوش خود ، واسط هوشمند اقدام به جستجو برای عبارتی فاقد "ء" می نماید. در این صورت نتایج جستجو ، صفحاتی را كه در محتوای متن آنها از "ء" استفاده نشده است نیز شامل می گردد.
د) استفاده از "ا" و "آ" :
در این مورد ، واسط ، بمحض برخورد به كلمه مورد كاوش كه در آن "ا" بصورت چسبان یا غیرچسبان بكار رفته باشد یا شامل "آ" باشد ، جستجو را به كاوش برای كلمات جدیدی كه با جایگزینی "ا" با "آ" ویا "آ" با "ا" ، ساخته شده اند ، بسط می دهد. در نتیجه كاوش برای كلمه "فرایند" ، صفحات حاوی كلمه "فرآیند" ، از دست نمی رود.
ه) استفاده از اصطلاحنامه(Thesaurus) برای حل مشكل تنوع املایی كلمات :این معضل شامل تنوع استفاده از "ی" در كلمات عربی مختوم به "ا" ، تنوع املایی بعضی كلمات كه همه درست هستند ، استفاده از كلمات اروپایی بصورت ترجمه فارسی و استفاده یا عدم استفاده از جمع مكسر برای بعضی كلمات می باشد كه حل مشكل كلیه موارد ، در ایجاد یك پایگاه داده در سمت خدمت گذار ، مستتر است. این پایگاه داده شامل نمایه ای از این كلمات و كلمات مترادف می باشد. برای مثال كلمه "موسی" ، به كلمه "موسا" و كلمه "كامپیوتر" به كلمه "رایانه" متناظر شده است. عامل هوشمند با مراجعه به این پایگاه داده ، برای عبارت مورد كاوش كاربر ، عبارات مشابهی استخراج كرده ، كاوش را به جستجو برای این عبارات ، علاوه بر عبارت اصلی ، بسط می دهد. ایجاد چنین پایگاه داده ای ، با مشاوره انجمن ها ، بزرگان و فرهنگستان ادب فارسی انجام می پذیرد و بروزآوری آن نیز بصورت دوره ای و با دخالت صاحب نظران مذكور صورت می گیرد.و) تبدیل كلمات اروپایی به رسم الخط فارسی با همان تلفظ اصلی(Cross language Retrieval ) :
كاربری كه بدنبال اطلاعاتی در خصوص برنامه های "Open Source" در اینترنت می باشد ، شاید برای همیشه از دسترسی به صفحاتی كه در آنها كلمه "سورس باز" بكار رفته است ، محروم بماند یا حداقل محكوم به اتلاف زمان زیادی تا رسیدن به چنین كلمه ای و به تبع ، نتایج مطلوب باشد. لذا در صورتی كه جستجو برای لغت "سورس" ، بنحوی همزمان با كاوش برای كلمه "Source" ، حتی بدون اطلاع كاربر ، انجام پذیرد ، می توان گفت هم در سرعت و هم در جامعیت اطلاعات بدست آمده ، ارتقایی صورت گرفته است.وظیفه واسط ما در این خصوص اینست كه با مراجعه به پایگاه داده ، كاوش را به كلمه ساخته شده بر اساس تلفظ انگلیسی متناظر نیز گسترش دهد. برای انجام فرآیند حل این مشكل بصورت اتوماتیك و ضمنا استفاده از پایگاه داده معتبرتر و روزآمدتر بعنوان معیار عملكرد این واسط ، می توان روشی پیشنهاد نمود كه كلمه متناظر تلفظ انگلیسی لغات كه با رسم الخط فارسی تهیه می گردد ، با مراجعه به پایگاه های داده بین الملی حاوی معادل های سمبولیك تلفظ كلمات انگلیسی (كه در كتاب های دیكشنری انگلیسی به انگلیسی آمده است) ، كلمه مذبور را تهیه نمود و سپس كاوش را برای آن انجام داد.پیشنهادات
مطالعه حاضر با هدف بهینه سازی امكانات جستجو و بازیابی اطلاعات در ابزارهای كاوش با واسط فارسی صورت گرفته است. بعنوان پژوهشی دیگر می توان تمهیداتی جهت كاوش هر چه دقیقتر وب های فارسی زبان ، با هدف به حداقل رساندن تاثیرهای سوء چالش های رسم الخط فارسی ، اندیشید و این راه حل ها را بصورت تلفیقی (سری و موازی) نیز استفاده نمود.می توان نرم افزار واسط كمك فارسی مذكور را بصورت یك نوار ابزار ، برروی Browser ، نصب و استفاده نمود. از طرف دیگر می توان بصورت یك نرم افزار كه بر روی Browser نصب شده بصورت پشت زمینه ، كلمات مورد كاوش را گرفته ، برروی آنها اعمال نظر كرده ، كاوش جدید خود را ترتیب دهد. پژوهشی دیگر می تواند در صورت امكان روشی را جستجو كند كه گراف معنایی مورد بحث را بصورت ماشینی ایجاد و گسترش دهد.
فهرست منابع
[۱] . Velasquez Juan , Hiroshi Yasuda , Terumasa Aoki , ۲۰۰۳ , Combinig the Web content and usage mining to understand the visitor behavior in a Web site , Third IEEE International Conference on Data Mining (ICDM&#۰۳۹;۰۳)
www.cs.wisc.edu/~shavlik/ICDM_۲۰۰۳_Schedule.pdf
[۲] . Chakrabarti S. , Martin van den Berg , Byron Domc , ۱۹۹۹ , Focused crawling: a new approach to topic-specific Web resource discovery , Computer Science and Engineering, Indian Institute of Technology, Bombay, ۴۰۰۰۷۶, India , FX Palo Alto Laboratory, ۳۴۰۰ Hillview Ave, Bldg ۴, Palo Alto, CA ۹۴۳۰۴, USA ,c IBM Almaden Research Center, ۶۵۰ Harry Rd, San Jose, CA ۹۵۱۲۰, USA
www.csd.uch.gr/~hy۵۵۸/papers/chakrabarti۹۹focused.pdf
[۳] . Feiyu Xu , ۲۰۰۱ , Overview of FASTUS , DFKI LT-Lab
www.ics.mq.edu.au/~diego/publications/ALTSS۰۳L۲.pdf
[۴] . Heflin J. , James Hendler , ۲۰۰۰ , Dynamic Ontologies on the Web ,Department of Computer Science University of Maryland College Park, MD ۲۰۷۴۲
www.cs.umd.edu/projects/plus/SHOE/pubs/aaai۲۰۰۰.pdf
[۵] . Dr. Osmar , R. Zaïane , ۲۰۰۲ , Principles of Knowledge Discovery in Data , Chapter ۹ www.cs.ualberta.ca/~joerg/courses/cmput۶۹۵/fall۲۰۰۳
[۶] اشرف زاده بهرام ، زبان فارسی در وبلاگ های فارسی ، ۱۳۸۳ ،
http://www.persianfarsi.com/articles/zabaneweblog.htm
[۷]. جعفرقلی بیگلو موسی ، ۱۳۸۲ ، مقایسه فرایند موضوع سازی ذهنی جویندگان اطلاعات با ساختار سرعنوان های موضوعی فارسی ، علوم اطلاع رسانی ، دوره ۱۴ ، شماره ۳و ۴.
[۸]. حسینی بهشتی ملوك السادات ،۱۳۸۳، كاربرد اصطلاح شناسی و واژه گزینی در نمایه سازی ماشینی و بازیابی اطلاعات ، عضو هیئت علمی مركز اطلاعات و مدارك علمی ایران ، علوم اطلاع رسانی ، دوره ۱۸ ، شماره ۳و ۴.
[۹]. خوانساری جیران ،۱۳۸۲ ، تكامل وب و مقایسه ابزارهای جستجو در اینترنت ، فصلنامه اطلاع رسانی ، دوره ۱۶ ، شماره ۳و۴ .
[۱۰]. رضازاده ملك رحیم ، ۱۳۸۰ ، تبیین و تدوین قواعد املای فارسی ، گلرنگ یكتا ، چاپ اول.
[۱۱]. سمایی سید مهدی ، عضو هیئت علمی مركز اطلاعات و مدارك علمی ایران۱۳۸۲، مفرد و جمع در نمایهسازی ، فصلنامه اطلاع رسانی. دوره ۱۶، شماره ۱و۲ ،
http://www.irandoc.ac.ir/ETELA-ART/۱۶/۱۶_۱_۲_۳.htm
[۱۲]فرهنگستان زبان و ادب فارسی ، ۱۳۸۳ ، دستور خط فارسی.
[۱۳]. كارنیرو آلبرتو ، ترجمه: علیرضا گنجی - دانشجوی كارشناسی ارشد كتابداری و اطلاعرسانی دانشگاه فردوسی مشهد ، ۱۳۸۳ ، نقش منابع هوشمند در مدیریت دانش ، فصلنامه اطلاع رسانی. دوره ۱۹، شمارهء ۳ و ۴
http://www.irandoc.ac.ir/etela-art/۱۹/۱۹_۳_۴_۹.htm
[۱۴] كمیجانی احمد ، ۱۳۸۲، ساختار نمایه سازی در موتورهای كاوش وب ، علوم اطلاع رسانی ، دوره ۱۷ شماره ۳و۴.
[۱۵]. كوشا كیوان۱۳۸۱، معیارهای ارزیابی ابزارهای كاوش اینترنت: مطالعه مقایسهایبر روی ابزارهای كاوش وب با واسط جستجوی فارسی ، نشر كتابدار – مجله كتابدار.
[۱۶]. محقق زاده محمد صادق - عضو هیات علمی دانشگاه علوم پزشكی شیراز ، زارعیان كاظم - كارشناس ارشد زبانشناسی ، ۱۳۸۳ ، ارائه راه حل برای برخی مسائل اتوماسیون و نگارش فارسی ، فصلنامه اطلاع رسانی. دوره ۱۹، شماره ۳ و۴ ،
http://www.irandoc.ac.ir/etela-art/۱۹/۱۹_۳_۴_۱.htm
[۱۷] . مرتضایی لیلا ، ۱۳۸۳ ، مسایل خط فارسی در ذخیره سازی و بازیابی اطلاعات ، فصلنامه اطلاع رسانی . دوره ۱۷ شماره ۱و۲ .
[۱۸]. هسی-یی اینگرید ، ترجمه: قاسم آزادی دانشجوی كارشناسی ارشد كتابداری و اطلاعرسانی دانشگاه تهران ، ۱۳۸۳ ، اینترنت : سازماندهی و جستجو ، فصلنامه اطلاع رسانی. دوره ۱۸، شماره ۳و ۴
http://www.irandoc.ac.ir/ETELA-ART/۱۸/۱۸_۳_۴_۱۰.htm
[۱۹]. محسنی یاسمن ، ایجاد و نمایش انتالوژی برای شبكه مفاهیم مرتبط با حوزه مخابرات نوری ، ۱۳۸۰ ، مرکز تحقیقات مخابرات ایران.
[۲۰]. عبدالهی بهناز ، بررسی روشهای طراحی و ایجاد انتولوژی ، ۱۳۸۰ ، مرکز تحقیقات مخابرات ایران.
[۲۱]. جباری فر معصومه ، بررسی پارامترهای ارزیابی و لیست دسته بندی شده جویشگرها ، ۱۳۸۰ ، مرکز تحقیقات مخابرات ایران.
[۲۲]. صالحی مازیار ، زارع بیدکی علی محمد ، ارائه RFP برای یک جویشگر دوزبانه فارسی/ انگلیسی ، ۱۳۸۰ ، مرکز تحقیقات مخابرات ایران.
[۲۳]. میریان مریم السادات ، ارائه چارچوب كلی برای زیرسیستمهای and Query Processing Information Retrieval ، ۱۳۸۰ ، مركز تحقیقات مخابرات ایران.
دكتر محسن صدیقی- عضو هیئت علمی دانشگاه صنعتی اصفهان
دكتر كامران زمانی فر- عضو هیئت علمی دانشگاه اصفهان
سید مجتبی شهیدی- دانشجوی كارشناسی ارشد دانشگاه آزاد نجف آباد
منبع : مركز اطلاعات و مدارك علمی ایران




همچنین مشاهده کنید


















































































































نمایندگی زیمنس ایران فروش PLC S71200/300/400/1500 | درایو …
دریافت خدمات پرستاری در منزل
pameranian.com
پیچ و مهره پارس سهند
خرید میز و صندلی اداری
خرید بلیط هواپیما
گیت کنترل تردد
غزه آمریکا طالبان توماج صالحی حجاب گشت ارشاد رهبر انقلاب سریلانکا کارگران پاکستان مجلس شورای اسلامی دولت
آتش سوزی کنکور سیل هواشناسی تهران سازمان سنجش شهرداری تهران پلیس سلامت فراجا قتل زنان
قیمت خودرو خودرو ارز قیمت دلار دلار قیمت طلا بازار خودرو بانک مرکزی ایران خودرو قیمت سکه مسکن سایپا
ترانه علیدوستی تلویزیون فیلم سینمای ایران مهران مدیری موسیقی کتاب تئاتر شعر
اسرائیل رژیم صهیونیستی روسیه فلسطین جنگ غزه حماس اوکراین طوفان الاقصی ایالات متحده آمریکا اتحادیه اروپا ترکیه عربستان
فوتبال پرسپولیس سردار آزمون استقلال بارسلونا بازی باشگاه پرسپولیس باشگاه استقلال فوتسال تراکتور لیگ برتر انگلیس تیم ملی فوتسال ایران
تیک تاک بنیاد ملی نخبگان ناسا وزیر ارتباطات عیسی زارع پور همراه اول تبلیغات اپل
مالاریا سلامت روان کاهش وزن استرس پیری داروخانه دوش گرفتن