یکشنبه, ۲۳ اردیبهشت, ۱۴۰۳ / 12 May, 2024
بررسی میزان اثربخشی عناصر ابرداده ای بر رتبه بندی

پژوهش حاضر با هدف تعیین میزان اثربخشی عناصر ابردادهای بر رتبهبندی صفحات وب توسط سه موتور کاوش عمومی «گوگل»، «یاهو»، و «اماسان» انجام پذیرفت. اثربخشی پنج عنصر ابردادهای نشانه عنوان زبان «اچ.تی.ام.ال»، ابرنشانههای کلیدواژهها و توصیف زبان «اچ.تی.ام.ال»، ابردادههای عنوان و موضوع از قالب ابردادهای «دابلین کور» که بر بازنمون موضوعی صفحات وب متمرکزند، با روش تجربی آزموده شد. ۸۴ صفحهٔ وب در گروههای گواه و آزمون به عنوان جامعهٔ مورد مطالعه تحت دامنهٔ فرعی http://metadata.irandoc.ac.ir منتشر شد. از میان موتورهای کاوش انتخابی، دو موتور کاوش یاهو و گوگل، صفحات را نمایهسازی کردند. کلیدواژههای منحصر به فرد و تکرار شونده که در مرحله طراحی در قالب عناصر ابردادهای به صفحات گروه آزمون افزوده شده بود، بررسی شد و میزان معنیداری تفاوت رتبه صفحات دو گروه با استفاده از آزمون غیرپارامتری «یو.من.وایتنی» محاسبه گردید. نتایج، نشانگر اثربخشی دو عنصر «عنوان» و «توصیف زبان اچ.تی.ام.ال» در هر دو موتور کاوش مورد مطالعه است. کلیدواژههای منحصر به فرد در ابرنشانه کلیدواژههای «اچ.تی.ام.ال» و ابرداده موضوع دابلین کور به بهبود رتبه صفحات در یاهو انجامید. در حالی که تکرار کلیدواژهها در بخش سرآیند صفحه وب، باعث بهبود رتبه در موتور کاوش یاهو شد، گوگل عملکردی معکوس داشت.
● مقدمه
همزمان با تولد وب، جهان شاهد تغییرات شگرفی در حوزهٔ ذخیره و بازیابی اطلاعات بوده است. هر روز بر تعداد صفحات وب افزوده می گردد و حجم وسیعی از اطلاعات، در بستر آن، به صورت ساختار نیافته [۲] (یالتاقیان[۳]، ۲۰۰۲) و فارغ از کنترل محتوایی و کتابشناختی منتشر میشود (زانگ و جاستریم [۴]، ۲۰۰۴؛ گوتلیب و الیوپولوس[۵] ، ۲۰۰۳). در چنین وضعیتی، مسئله اساسی، چگونگی کنترل و مدیریت بدنهٔ ساختارنیافته و رشد سریع این بدنه است (اسدی و جمالی مهمویی،[۶] ۲۰۰۴). تاکنون ابزارهای کاوش[۷] از قبیل «موتورهای کاوش»[۸] «ابرموتورهای کاوش»،[۹] «راهنماهای موضوعی» [۱۰] و «نرمافزارهای کاوش»[۱۱] محیط مجازی وب را تا اندازه ای تحت کنترل و مدیریت خویش درآوردهاند.
کاربران از میان ابزارهای رایج کاوش، موتورهای کاوش را به عنوان نقطه آغازین ورود به اینترنت تلقی می کنند (اسپینک و دیگران[۱۲]، ۲۰۰۱ نقل در دوال و واگان [۱۳]، ۲۰۰۴؛ بار- ایلان[۱۴] ، ۲۰۰۵؛ زانگ و دیمیتروف[۱۵]، ۲۰۰۴)، بیش از ۹۵% ترافیک کاوش در اینترنت به موتورهای کاوش مربوط است و ۸۰% کاربران، اطلاعات مورد نیاز خود را از طریق موتورهای کاوش به دست می آورند (هاتلی[۱۶] ، ۲۰۰۲ نقل در زانگ و دیمیتروف،a ۲۰۰۵ (. یافتن اطلاعات موضوعی ویژه در وب دشواریهایی دارد و هر روز بر حجم این دشواریها افزوده میگردد (دروت[۱۷]، ۲۰۰۰، ص۲۰۹). تعداد نتایج بازیابی شدهٔ موتورهای کاوش، اغلب چنان فراوان است که کاربر عملاً جز مرور چند صفحه نخست نتایج، از سایر صفحات منصرف میشود (جانسن، اسپینک، و ساراسویک،[۱۸] ۲۰۰۰؛ فدایی عراقی[۱۹]، ۲۰۰۵، ص۱۳؛ یالتاقیان، ۲۰۰۲) و به ناچار به رتبهبندی[۲۰] ارائه شدهٔ موتورهای کاوش اعتماد میکند (بارـ ایلان، ۲۰۰۵).در این وضعیت، چنانچه صفحه ای مرتبط، در رتبههای اول جای نگیرد، ممکن است از دید کاوشگر پنهان بماند (زانگ و جاستریم ، ۲۰۰۵، ص۹۲؛ گوتلیب و الیوپولوس، ۲۰۰۳).
از سویی، یکی از اولین دغدغههای ناشران وبسایتها دستیابی به رتبههای برتر در میان وبسایتهای مشابه و هم موضوع است. بدین منظور همواره سیاههای از عناوین،[۲۱] کلیدواژهها[۲۲] و توصیفهایی[۲۳] که احتمال کسب رتبههای برتر را دارند، تهیه و در طراحی صفحات لحاظ میشود (ریچاردسون،[۲۴] ۲۰۰۳ نقل در زانگ و دیمیتروف، a۲۰۰۵). طراحی نرمافزارهایی چون «تحلیلگر چگالی کلیدواژه»،[۲۵] «ورد ترکر»،[۲۶] «وب پزیشن گولد»،[۲۷] و شکلگیری و گسترش وبسایتهایی که خدمات توصیهای و مشاورهای بهینهسازی صفحات[۲۸] را به منظور کسب رتبههای برتر در موتورهای کاوش ارائه می دهند، تأییدی بر حساسیت و توجه به این مسئله است.
نتایج تحقیقات، تفاوتهای قابل ملاحظهای را میان الگوریتمهای رتبهبندی موتورهای کاوش عمومی نشان میدهد (بار ـ ایلان، ۲۰۰۵). اطلاعات مربوط به الگوریتمهای رتبهبندی موتورهای کاوش به صورت طبقه بندی شده[۲۹] و به عنوان اسرار تجاری [۳۰] محافظت میشود. حفظ حالت رقابتی و جلوگیری از سوء استفادهٔ طراحان وبسایتها از این اطلاعات، از جمله دلایل حفاظت هستند (بارـ ایلان، ۲۰۰۵،ص۱۵۱۲). با وجود ابهامهای موجود در زمینه الگوریتم، رتبهبندی موتورهای کاوش، پژوهش پیرامون چگونگی رتبهبندی نتایج متوقف نشده است و تلاشهایی در زمینه کشف عوامل اثرگذار و تعیین میزان اثرگذاری آن عوامل، انجام پذیرفته است (ترنر و برک بیل[۳۱]، ۱۹۹۸؛ زانگ و دیمیتروف، ۲۰۰۴؛ a۲۰۰۵، b۲۰۰۵، صفری[۳۲]، ۲۰۰۵؛ محمد[۳۳]، ۲۰۰۶؛ هنشا و والاسکاس[۳۴] ،۲۰۰۱).
● محدودهٔ بررسی
صفحات وب متشکل از سه جزء اند: ۱. معنا[۳۵] یا محتوا[۳۶] ۲. بستر نحوی[۳۷] یا ساختار[۳۸] و ۳. پیوندهای فرامتنی[۳۹]. محتوا در بستر نحوی زبانهای نشانه گذاری[۴۰] که قالب یا ساختار ارائه محتوا را فراهم میآورند، جای میگیرد و ارتباط میان اجزای اطلاعاتی از طریق پیوندهای فرامتنی حاصل میشود. هر یک از این عناصر - محتوا، ساختار و پیوندهای فرامتنی ـ ویژگیهای خاصی دارند که بستر ارزیابی صفحات را فراهم می آورد و به طور بالقوه در بهبود کیفی رتبهبندی حاصل از کاوش اثر گذار است (کوودو-تررو[۴۱]، ۲۰۰۴).
گوگل بیش از هزار عامل را در نظام رتبهبندی نتایج خود مدنظر دارد، اما به دلیل ماهیت تجاری و حفظ یکپارچگی نتایج کاوش، از ذکر جزئیات بیشتر خودداری میکند (گوگل[۴۲]، ۲۰۰۴). توافقی بر سر مؤثرتر بودن یک عامل نسبت به سایر عوامل وجود ندارد (فیشکین[۴۳]، ۲۰۰۵) و هر یک از موتورهای کاوش، الگوریتم رتبهبندی خاصی را دنبال میکنند (هنشا و والاسکاس، ۲۰۰۱، ص۹۲). با وجود این، ساختار ابردادهای،[۴۴] محتوای صفحه[۴۵] و (عوامل داخلی)، و وضعیت ارجاعات فرامتنی[۴۶] وـ (عوامل خارجی) - از جمله عوامل مؤثر بر رتبهبندی ذکر شده است (زانگ و جاستریم، ۲۰۰۵).
در این پژوهش، از میان عوامل مؤثر شناخته شده بر رتبهبندی نتایج کاوش، تمرکز بر عناصر ابردادهای[۴۷] است و از میان عناصر ابردادهای، پنج عنصر به عنوان معیار ربط فنی[۴۸] انتخاب شده و میزان اثرگذاری هر یک (به صورت منحصر به فرد و در صورت تکرار) بر رتبهٔ صفحات بازیابی شده توسط موتورهای کاوش عمومی، بررسی و تجزیه و تحلیل شده است. عناصر ابردادهای مورد بررسی در این پژوهش عبارتند از: نشانه عنوان[۴۹] از زبان «اچ.تی.ام.ال»، ابرنشانههای کلیدواژهها[۵۰] و توصیف[۵۱] از زبان «اچ.تی.ام.ال»، دو ابردادهٔ عنوان[۵۲] و موضوع[۵۳] از قالب ابردادهای دابلین کور.
اگر چه نشانه عنوان زبان «اچ.تی.ام.ال»، عنصر ابردادهای محسوب نمیشود؛ اما به واسطه اهمیت ویژه اش (سالیوان[۵۴]، ۲۰۰۲؛ نوروزی[۵۵]، ۲۰۰۵) در میان سایر نشانههای «اچ.تی.ام.ال»، در کنار چهار عنصر ابردادهای دیگر بررسی شده است.
پنج عنصر منتخب، تنها تعدادی از عناصر ابردادهای موجود در قالب ابردادهای دابلین کور و زبان «اچ.تی.ام.ال» هستند. این عناصر بر بازنمون موضوعی مدرک متمرکزند و در برخی منابع، کاربرد آنها توصیه شده است (زانگ و دیمتروف، ۲۰۰۴ ؛ سالیوان، ۲۰۰۲؛ لی اسملتزر[۵۶]، ۲۰۰۰، ص۲۰۶؛ والکی، فریر[۵۷]، ۲۰۰۱، ص۲۷۲).
● پرسشهای اساسی
پژوهش حاضر فاقد فرضیه است و پرسشهای اساسی آن بدین قرار است:
۱) حضور کلیدواژهٔ مورد کاوش در هر یک از عناصر مورد بررسی (نشانه عنوان، ابرنشانههای کلیدواژهها و توصیف زبان نشانه گذاری فرامتن، ابردادههای عنوان و موضوع قالب ابردادهای دابلین کور) تا چه میزان بر رتبهبندی صفحات در سه موتور کاوش مورد آزمون اثرگذار است؟
۲) تکرار کلیدواژهٔ مورد کاوش در دو تا پنج عنصر یاد شده در بخش سرآیند[۵۸] صفحه و صرفنظر از نوع عنصر، تا چه میزان بر بهبود رتبهٔ صفحه اثرگذار است؟
●روششناسی
پژوهشهایی که به تعیین میزان اثربخشی عناصر ابردادهای بر رتبهبندی صفحات وب در موتورهای کاوش پرداختهاند، با تفاوتهایی اندک، از روش تجربی بهره برده اند.در این پژوهش نیز با آگاهی از وجود سایر عواملی که بر رتبهبندی صفحات اثرگذارند، جهت اعمال متغیرهای مستقل، کنترل متغیرهای دخیل، و مشاهدهٔ تغییرات در متغیر وابسته، از روش تجربی استفاده کردهایم.
جامعهٔ مورد پژوهش، نشریه ای الکترونیکی با ۸۴ صفحهٔ وب است که پژوهشگر آن را طراحی کرده است. این نشریه با روندی که در ادامه میآید، طراحی شد و سپس در معرض نمایه سازی موتورهای کاوش قرار گرفت.
۱) مراحل طراحی صفحات
در مرحله نخست، تعداد چهارده مقاله در موضوعات وب معنایی[۵۹]، هستیشناختی[۶۰]، وبسنجی[۶۱] و ابردادههای دابلین کور از میان مقالات منتشر شده در نشریات رایگان حوزهٔ کتابداری و اطلاعرسانی که در فهرست راهنمای نشریات پیوسته رایگان[۶۲] معرفی شده است، انتخاب گردید.
کلیدواژههای نمایهای این مقالات به شیوهٔ کنترل نشده (زبان طبیعی) و از بستر عنوان، کلیدواژهها (در صورت وجود) چکیده، و در برخی موارد متن مقاله برگزیده شد.
پژوهش بر دو دسته کلیدواژه متمرکز است:
الف) کلیدواژههای منحصر به فرد و ب) کلیدواژههای تکرارشونده. کلیدواژههای منحصر به فرد آن دسته از کلیدواژههایی هستند که منحصراً به یک عنصر ابردادهای اختصاص یافتهاند؛ با دیگر کلیدواژههای مربوط به سایر عناصر، همپوشانی و شباهت ندارند و پاسخگویی به نخستین پرسش را ممکن میسازند. کلیدواژههای تکرارشونده، کلیدواژههایی هستند که در تمام عناصر ابردادهای به یک شیوه و ترتیب، قبل از کلیدواژههای منحصر به فرد و به منظور سنجش اثربخشی تکرار کلیدواژهها در دو تا پنج عنصر ابردادهای (پرسش دوم) افزوده شدهاند.
به طور نمونه، کلیدواژههای منحصر به فرد و تکرار شوندهٔ مقاله هشتم با عنوان «A Metadata Registry for the Semantic Web» در جدول ۱ آمده است.
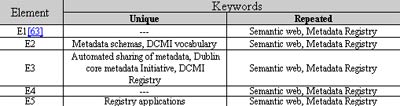
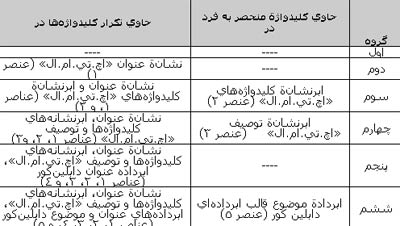
در گروه دوم
<TITLE>A Metadata Registry for the Semantic Web</TITLE>
در گروه سوم
<TITLE>A Metadata Registry for the Semantic Web</TITLE>
<META name="keywords" content="Semantic web, Metadata Registry, Metadata schemas, DCMI vocabulary">
در گروه چهارم
<TITLE>A Metadata Registry for the Semantic Web</TITLE>
<META name="keywords" content="Semantic web, Metadata Registry, Metadata schemas, DCMI vocabulary">
<META name="description" content="Semantic web, Metadata Registry, Automated sharing of metadata, Dublin core metadata Initiative, DCMI Registry">
در گروه پنجم
<TITLE>A Metadata Registry for the Semantic Web</TITLE>
<META name="keywords" content="Semantic web, Metadata Registry, Metadata schemas, DCMI vocabulary">
<META name="description" content="Semantic web, Metadata Registry, Automated sharing of metadata, Dublin core metadata Initiative, DCMI Registry">
<META name="DC.Title" content="A Metadata Registry for the Semantic Web">
در گروه ششم
<TITLE>A Metadata Registry for the Semantic Web</TITLE>
<META name="keywords" content="Semantic web, Metadata Registry, Metadata schemas, DCMI vocabulary">
<META name="description" content="Semantic web, Metadata Registry, Automated sharing of metadata, Dublin core metadata Initiative, DCMI Registry">
<META name="DC.Title" content="A Metadata Registry for the Semantic Web">
<META name="DC.Subject" content="Semantic web, Metadata Registry, Registry applications">
۲) انتشار صفحات طراحی شده
بدین ترتیب، ۸۴ صفحه ایستا[۶۵] به کمک واژهپرداز Word از مجموعه مایکروسافت آفیس ۲۰۰۳،[۶۶] طراحی و از۲۴ خرداد تا ۸ شهریور۱۳۸۵[۶۷] در دامنه فرعی «ابرداده» از سایت «پژوهشگاه اطلاعات و مدارک علمی ایران»[۶۸] منتشر شد و در معرض نمایه سازی سه موتور کاوش گوگل[۶۹]، یاهو[۷۰]، ام اس ان[۷۱] سه موتور کاوش پراستفاده به استناد «الکسا»،[۷۲] «سرچ اینجین واچ»،[۷۳] «سرچ اینجین گاید»[۷۴] و سایتهای مشابه[۷۵] ـ قرار گرفت. در دهمین روز انتشار صفحات، موتور کاوش گوگل، تمامی صفحات منتشر شده را نمایهسازی نمود؛ این در حالی است که یاهو روندی کندتر داشت و پس از گذشت بازه زمانی مشخص شده، ۷۶ صفحه مربوط به مقالات نشریه نمایه شد. اما از میان سه موتور کاوش انتخابی، «ام.اس.ان» به دلیل عدم نمایه سازی تعداد قابل قبولی از صفحات در مدت زمان تعیین شده، از مجموعه پژوهش حذف شد و ادامهٔ پژوهش با تمرکز بر صفحات نمایه شده، در دو موتور کاوش یاهو و گوگل انجام پذیرفت.
۳) گردآوری دادهها
به منظور تعیین میزان اثربخشی عناصر ابردادهای در این مرحله از پژوهش، کاوش کلیدواژه ای در کادر محاورهای ساده[۷۶] دو موتور کاوش گوگل و یاهو انجام پذیرفت. از آنجا که دو گروه گواه و آزمون، در وب سایت طراحی شده گنجانده شده است و نیازی به تعیین رتبهٔ صفحات در میان سایر صفحات موجود در وب نیست، کاوش کلیدواژه ای در دامنه وب سایت طراحی شده محدود گردید. فرمول کاوش در موتورهای کاوش گوگل و یاهو به ترتیب، چنین است:
Site:metadata.irandoc.ac.ir Keywords یا Domain:metadata.irandoc.ac.ir Keywords
















































































































































نمایندگی زیمنس ایران فروش PLC S71200/300/400/1500 | درایو …
دریافت خدمات پرستاری در منزل
پیچ و مهره پارس سهند
تعمیر جک پارکینگ
خرید بلیط هواپیما
ایران مجلس شورای اسلامی مجلس صادق زیباکلام انتخابات مجلس دوازدهم انتخابات مجلس انتخابات مجلس دوازدهم دولت انتخابات مجلس شورای اسلامی ستاد انتخابات کشور رهبر انقلاب
قتل تهران هواشناسی فضای مجازی سیل شهرداری تهران زلزله سازمان هواشناسی پلیس وزارت بهداشت آتش سوزی سلامت
قیمت طلا خودرو کارت سوخت قیمت خودرو قیمت دلار بازار خودرو گاز حقوق بازنشستگان بورس نمایشگاه نفت ایران خودرو بانک مرکزی
نمایشگاه کتاب کتاب نمایشگاه کتاب تهران رضا عطاران کیانوش عیاری کتابخانه سینمای ایران تلویزیون دفاع مقدس سینما نمایشگاه بینالمللی کتاب تهران سریال
دانش بنیان تجهیزات پزشکی فناوری
رژیم صهیونیستی اسرائیل غزه فلسطین جنگ غزه آمریکا حماس روسیه افغانستان سازمان ملل اوکراین رفح
فوتبال پرسپولیس استقلال رئال مادرید لیگ برتر بازی هوادار باشگاه پرسپولیس لیگ برتر فوتبال ایران لیگ برتر ایران سپاهان باشگاه استقلال
هوش مصنوعی همراه اول شفق قطبی خورشید دبی ایالات متحده ایلان ماسک نوآوری ناسا تبلیغات اپل گوگل
سرطان درمان و آموزش پزشکی خواب زیبایی دیابت فشار خون کاهش وزن بارداری توت فرنگی