پنجشنبه, ۲۵ بهمن, ۱۴۰۳ / 13 February, 2025
یک سیستم فایل موازی نسل جدید برای کلاسترهای لینوکس

دانشمندان علوم کامپیوتر از کامپیوترهای عظیم موازی به منظور شبیه سازی رویدادهایی که در دنیای واقعی رخ می دهند استفاده می کنند. این اعمال در چنین مقیاس بزرگی جهت درک بهتر نمودهای علمی یا پیش بینی رفتارها لازم و ضروری می باشند. در اغلب موارد منابع محاسباتی یک فاکتور محدود کننده در حوزه این شبیه سازی ها محسوب می گردند. منابع محدود تنها شامل CPU و حافظه نمی شوند، بلکه این منابع زیرسیستم های ورودی/خروجی را نیز در بر می گیرند، چرا که چنین برنامه هایی معمولا حجم زیادی از داده را تولید و یا پردازش می نمایند. برای اینکه روند شبیه سازی با سرعت بالا اجرا شده و ادامه یابد، سیستم ورودی/خروجی بایستی قادر به ذخیره صدها مگابایت داده در هر ثانیه باشد، و در این عملیات باید دیسک های زیادی مورد استفاده قرار گیرد. نرم افزاری که این دیسک ها را به صورت یک سیستم فایل مرتبط سازماندهی می کند یک "سیستم فایل موازی" نامیده می شود.
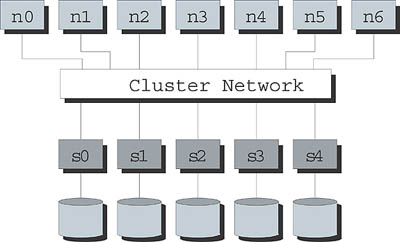
سیستم های فایل موازی بویژه به منظور فراهم نمودن ورودی/خروجی های بسیار سریع در مواقعی که بایستی توسط پردازش های زیادی در یک لحظه مورد دسترسی قرار گیرند طراحی شده اند. این پردازش ها میان چندین کامپیوتر مختلف، یا میان گره ها(nodes)، که کامپیوتر موازی را تشکیل می دهند توزیع گردیده است. شکل ۱ یک نمای سطح بالا از یک کامپیوتر موازی به همراه یک سیستم فایل موازی را نمایش می دهد. گره هایی که کار محاسبه را انجام می دهند به یکدیگر متصل شده اند و از سوی دیگر توسط شبکه کلاستر به گره های سرور ورودی/خروجی مرتبط هستند، و داده را بر روی دیسک های الصاقی به گره های سرور ذخیره می نمایند.
لازم نیست که شما برای بهره بردن از یک سیستم فایل موازی در یک لابراتوار ملی، که دارای یک کلاستر ۱۰۰۰ گره ای است، مشغول به کار باشید. برای سالها سیستم فایل موازی مجازی (PVFS) مخصوص کلاسترهای لینوکس در دسترس بوده است، که به هر شخصی امکان برپا کردن و استفاده از همان سیستم فایل موازی که در حال حاضر بر روی کلاسترهای بزرگ فراوانی در سراسر دنیا مورد استفاده قرار می گیرند را می دهد. اخیرا یک سیستم فایل موازی کامل تر و جدیدتر بنام PVFS۲ عرضه شده است. این سیستم فایل جدید دارای انعطاف پذیری بیشتری بوده، و بهره بیشتری از سخت افزار موجود در کلاسترهای امروزی می برد، با کلاسترهای بزرگتر مطابقت بیشتری دارد، و مدیریت آن نسبت به نسل قبل ساده تر است.
● مفاهیم سیستم فایل موازی
در مقابل، سیستم های فایل شبکه ای دارای نقش متفاوتی هستند. امروزه، داشتن یک پیکربندی از چندین ماشین با برخی از انواع ذخیره سازی اشتراکی یا سیستم فایل همچون NFS، Windows Networking یا AppleTalk دیگر امر غیر عادی محسوب نمی شود. این سیستم ها با توجه به پیشرفت های حاصل شده در کارآیی آنها (پیشرفت هایی نظیر عمل کش کردن سمت کلاینت) به خوبی home directory ها کار خود را انجام می دهند. کش سازی سمت کلاینت تاریخچه تغییرات محلی فایل را بدون بروزرسانی بیدرنگ در وضعیتی که داده بر روی سرور و یا بر روی حافظه های کش موجود بر روی سایر کلاینت ها ذخیره شده باشد نگه داری می کند. این رویکرد بطور کلی بارگذاری های شبکه را کاهش داده و سرعت انجام اعمال معمولی از قبیل ویرایش یا کامپایل فایل ها را به روشی که هزینه های شبکه را تقریبا شفاف می سازد افزایش می دهد.
در حالی که مزیت کش سازی سمت کلاینت در سیستم های فایل شبکه ای بر کسی پوشیده نیست، برنامه های موازی در صورتیکه داده ارائه شده به آنها ناهماهنگ و متناقض باشد می توانند نتایج نادرستی را تولید نمایند. اگر پردازش ها همواره یک دید مشترک از داده را به اشتراک گذارند، برنامه های موازی قادر خواهند بود بدون خطا به کار خود ادامه دهند. یک روش، حصول اطمینان از این مسئله است که حافظه های کش موجود در هر گره همواره حاوی آخرین داده است. تکنیک های گوناگونی برای حفظ هماهنگی و سازگاری وجود دارد، که توسط هر تکنیک به مشخصه های متفاوتی از کارآیی می توان دست یافت.
برای مثال، برخی سیستم های فایل کلاستر مسئله سازگاری و هماهنگی داده را با استفاده از قفل های فایل به منظور جلوگیری از دستیابی همزمان به فایل حل می کنند. بطور کلی، قفل ها روشی برای حصول اطمینان از این مطلب هستند که تنها یک فرایند در یک لحظه قادر به اعمال تغییرات بر روی داده است. در یک سیستم فایل شبکه ای، معمولا یک قفل بایستی از یک مدیر قفل مرکزی کسب اجازه نماید. قفل های فایل نوع Coarse-grained تضمین می کنند که فقط یک پردازش در یک لحظه قادر به نوشتن داده در یک فایل باشد. کارآیی با افزایش تعداد پردازش ها تنزل خواهد یافت. سایر روش ها شامل طرح های قفل فایل fine-grained، همچون قفل محدوده بایت (byte-range)، می باشند که این امکان را فراهم می آورند که چندین پردازش بصورت همزمان نواحی مختلفی از یک فایل به اشتراک گذاشته شده را بنویسند. به هر حال، آنها با محدودیت های مقیاس پذیری ((scalability نیز مواجه می شوند. بالاسری (overhead) ناشی از نگهداری تعداد زیادی از قفل های از این نوع در نهایت به تنزل کارآیی ختم می گردد. در حالت کلی تر، هر سیستم قفل شبکه ای با یک گلوگاه محدود کننده برای دسترسی داده مواجه می شود. برای دستیابی به مقیاس پذیری و کارآیی در مورد درخواست های برنامه هایی که اعمال ورودی/خروجی زیادی دارند، یک سیستم بدون بالاسری قابل توجه (همچون قفل کردن) و بدون عرضه متفاوت داده میان گره ها (همچون کش سازی سمت کلاینت) مورد نیاز است. برنامه های موازی تمایل دارند که هر فرایند را وادار به نوشتن در نواحی مجزایی از یک فایل به اشتراک گذاشته شده نمایند. برای این نوع برنامه ها، در حقیقت هیچ نیازی به عمل قفل کردن نیست، و ما می خواهیم که تمام اعمال نوشتن بصورت موازی و بدون تاخیر موجود در چنین رویکردهایی ادامه یابد.
بجای داشتن یک سیستم فایل با کارآیی بالا که زمان زیادی را صرف مجادله برای منابع مشترک یا تلاش برای حفظ سازگاری و هماهنگی حافظه های کش کند، حالت ایده آل این است که سیستمی را طراحی کنیم که به اشتراک گذاری منابع و سازگاری مناسب را پشتیبانی نماید. PVFS۲ مثالی از یک سیستم فایل موازی نسل آینده است که برای برآورده ساختن این موارد طراحی شده است. در قسمت بعد به بحث در مورد چگونگی راه اندازی PVFS۲ خواهیم پرداخت.
● سیستم PVFS۲
PVFS۲ نشان می دهد که ساختن یک سیستم فایل موازی که بصورت مجازی با پی ریزی دقیق فوق داده و فضانام و همچنین تعریف معانی دستیابی داده که می تواند بدون قفل کردن در دسترس قرار گیرد سازگاری را حفظ کند، امکانپذیر است. این طراحی به بروز برخی از رفتارهای سیستم فایل که مورد انتظار تعدادی از برنامه های سنتی نیست ختم می شود. این معانی در زمینه ورودی/خروجی موازی بحث جدیدی به شمار نمی روند. PVFS۲ بصورت دقیق تر معانی را که توسط MPI-IO، یک API ورودی/خروجی با کارآیی بالا، دیکته می شود پیاده سازی می نماید.
PVFS۲ همچنین دارای پشتیبانی محلی برای الگوهای انعطاف پذیر ناپیوسته دستیابی داده می باشد. اغلب برنامه های سنتی (نظیر "cat" و "vi") به نواحی داده پیوسته از فایل های باز شده دسترسی دارند، در حالیکه برنامه های علمی اغلب اوقات نیازمند الگوهای دستیابی هستند که ناپیوسته باشند. برای مثال، شما می توانید برنامه ای را تصور نمایید که ستونی از عناصر خارج از یک آرایه را می خواند. برای بازیابی این داده، برنامه ممکن است تعداد زیادی عمل خواندن کوچک و پراکنده را بر روی سیستم فایل انجام دهد. در صورتیکه، اگر بتواند طی یک مرحله تمامی عناصر ناپیوسته را از سیستم فایل درخواست نماید، هم سیستم فایل و هم برنامه به نحو کارآمد تری وظیفه خود را انجام خواهند داد (شکل ۲ را ببینید).
علاوه بر کارآیی، ثبات و مقیاس پذیری scalability)) نیز اهداف مهم طراحی به شمار می آیند. به منظور کمک به دستیابی به این اهداف، PVFS۲ بر اساس یک معماری مستقل از وضعیت ((stateless طراحی گردیده است. این به آن معنی است که سرورهای PVFS۲ تاریخچه مربوط به اطلاعات سیستم فایل، اطلاعاتی مانند اینکه کدام فایل ها باز شده اند یا موقعیت فایل ها و مواردی از این قبیل، را نگهداری نمی کنند. همچنین در این مورد هیچ وضعیت قفل مشترکی برای مدیریت وجود ندارد. مزیت اصلی یک معماری مستقل از وضعیت این است که در آن کلاینت ها قادرند بدون بهم زدن کل سیستم دچار خطا شده و مجددا به کار خود ادامه دهند. این معماری همچنین به PVFS۲ این امکان را می دهد که در مواجهه با صدها سرور و هزاران کلاینت بدون اینکه تحت فشار بالاسری و پیچیدگی پیگیری وضعیت فایل یا اطلاعات قفل متعلق به کلاینت های مذکور قرار گیرد وظیفه خود را بدرستی انجام دهد.
بر خلاف PVFS نسل گذشته، PVFS۲ دارای یک سیستم شبکه ای و ذخیره سازی ماژولار است. یک سیستم ذخیره سازی ماژولار این امکان را برای چندین back-end ذخیره سازی فراهم می آورد که به راحتی به PVFS۲ متصل شوند. این خاصیت تلفیقی کار افرادی را که در حال تحقیق بر روی ورودی/خروجی به منظور آزمایش و تجربه تکنیک های مختلف ذخیره سازی هستند ساده می سازد. همچنین یک سیستم شبکه ای ماژولار اجازه کار بر روی اتصالی از شبکه های چندگانه را داده و فرایند افزودن پشتیبانی برای انواع دیگری از شبکه ها را آسان می نماید. PVFS۲ در حال حاضر TCP/IP و همچنین شبکه های Infinibandو Myrinet را پشتیبانی می کند.
این طراحی ها PVFS۲ را قادر به انجام وظایف خود به نحو عالی در یک محیط موازی می سازد، اما در وضعیتی که به عنوان یک سیستم فایل محلی مورد استفاده قرار گیرد کار خود را به خوبی قبل انجام نخواهد داد. بدون کش سازی فوق داده سمت کلاینت، برخی اعمال زمان زیادی صرف می کنند.این امر می تواند مدت زمان انجام برنامه هایی همچون "ls" را بیشتر از حد انتظار افزایش دهد. با وجود این محدودیت، PVFS۲ برای برنامه هایی که دارای اعمال ورودی/خروجی زیادی هستند مناسب تر است، تا اینکه برای میزبانی یک home directory مورد استفاده قرار گیرد. PVFS۲ برای خواندن و نوشتن کارآمد حجم زیادی از داده بهینه شده است، و از اینرو بسیار مناسب برنامه های علمی می باشد.
مترجم: امین ایزدپناه





































































ایران مسعود پزشکیان دولت چهاردهم پزشکیان مجلس شورای اسلامی محمدرضا عارف دولت مجلس کابینه دولت چهاردهم اسماعیل هنیه کابینه پزشکیان محمدجواد ظریف
پیاده روی اربعین تهران عراق پلیس تصادف هواشناسی شهرداری تهران سرقت بازنشستگان قتل آموزش و پرورش دستگیری
ایران خودرو خودرو وام قیمت طلا قیمت دلار قیمت خودرو بانک مرکزی برق بازار خودرو بورس بازار سرمایه قیمت سکه
میراث فرهنگی میدان آزادی سینما رهبر انقلاب بیتا فرهی وزارت فرهنگ و ارشاد اسلامی سینمای ایران تلویزیون کتاب تئاتر موسیقی
وزارت علوم تحقیقات و فناوری آزمون
رژیم صهیونیستی غزه روسیه حماس آمریکا فلسطین جنگ غزه اوکراین حزب الله لبنان دونالد ترامپ طوفان الاقصی ترکیه
پرسپولیس فوتبال ذوب آهن لیگ برتر استقلال لیگ برتر ایران المپیک المپیک 2024 پاریس رئال مادرید لیگ برتر فوتبال ایران مهدی تاج باشگاه پرسپولیس
هوش مصنوعی فناوری سامسونگ ایلان ماسک گوگل تلگرام گوشی ستار هاشمی مریخ روزنامه
فشار خون آلزایمر رژیم غذایی مغز دیابت چاقی افسردگی سلامت پوست