جمعه, ۲۱ دی, ۱۴۰۳ / 10 January, 2025
انبار داده ها
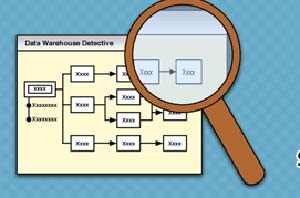
● مقدمه
یک انبار داده (Data warehouse) ، مخزنِ اصلی دادههای تاریخی یک سازمان یا حافظهی مشترک و گروهیِ(Corporate memory ) آن است. این انبار شامل مواد خام برای سیستم حمایت تصمیمگیری مدیریتی یاDSS (Decision Support Systems) میباشد. فاکتور اصلیای که منجر به استفاده از یک انبار داده(Data Warehouse) میشود این است که یک تحلیلگر میتواند آنالیزها و جستجوهای پیچیدهای مثل استخراج داده(Data Mining) را روی اطلاعات انجام دهد بدون اینکه سیستمهای اجرایی (Operational Systems)کند شوند.
Bill Inmon، از اولین کاربرهای این مبحث، یک انبار داده (Data Warehouse) را با واژههای زیر تعریف کرده است:
▪ Subject-Oriented* (مرتبط با موضوع)
دادهها در یک انبار داده(Data Warehouse) به نحوی سازماندهی میشوند که تمام اجزای داده که با همان واقعه یا موضوع مرتبط هستند، به هم متصل باشند.
▪ Time-Variant* (متغیر با زمان)
تغییرات دادهها در یک انبار داده(Data Warehouse)، ردیابی و ثبت میشوند تا امکان تهیهی گزارشهایی که تغییرات را در طول زمان نشان میدهند، فراهم شود.
▪ Non-Volatile* (غیر فرار)
دادههای موجود در انبار داده(Data Warehouses)، هیچگاه دوباره نویسی یا پاک نمیشوند، داده(Data) ثابت و بدون تغییر است اما برای گزارشهای آینده حفظ میشود.
▪ Integrated* (منسجم)
انبار دادهها(Data Warehouses) حاوی دادههایی از همه یا اکثریت فعالیتهای اجزای سازمان میباشد و این داده ها پایدار است.
بعنوان مثال یک انبار داده ممکن است برای یافتن روزی از هفته که در آن یک شرکت حداکثر فروش را در ماه مِی ۱۹۹۲ کرده است به کار برود و یا چگونه مرخصی بیماری کارمندان در هفتهی قبل از تعطیلات زمستانی بین کالیفورنیا و نیویورک از ۲۰۰۱-۲۰۰۵ متفاوت بود.
در حالیکه سیستمهای اجرایی برای سهولت استفاده و سرعت اصلاحات از طریق استفاده از نرمالسازی بانک داده و یک مدل رابطهی وجودی بهینه شدهاند، انبار داده برای گزارشدهی و آنالیز بهینه شده است.
اغلب، دادههای موجود در انبار دادهها به شدت دِنورمالیزه (غیر نرمالیزه) هستند و یا خلاصه شدهاند و یا براساس یک مدلِ مبتنی بر بُعد ذخیره شدهاند. با این وجود، این همیشه منجر به دستیابی به زمانهای پاسخدهی و جستجوی قابل قبول نمیشود.
● HISTORY ( تاریخچه)
انبار دادهها(Data Warehouses) در اواخر دههی۸۰ و اوایل دههی ۹۰ به نوع خاصی از (Computer Databases) مبدل شد. این انبارها به منظور برآورده کردن تقاضای روزافزون برای کنترل اطلاعات و آنالیز ایجاد شدند که توسط سیستمهای اجرایی قابل برآورده سازی نبود.
سیستمهای اجرایی(Operational Systems) به دلایل مختلف قادر به تأمین این نیاز نبودند
۱) بار ِ ناشی از فرآیند گزارشدهی سبب کاهش سرعت پاسخدهی سیستمهای اجرایی میشد.
۲) طراحی بانک دادهها(Databases) در سیستمهای اجرایی برای آنالیز اطلاعات و گزارشدهی بهینهسازی نشده بود.
۳) اکثر سازمانها بیش از یک سیستم اجرایی داشتند بنابراین گزارشدهی در سطح کل سازمان توسط یک سیستم واحد امکانپذیر نبود.
۴) ایجاد گزارش در سیستمهای اجرایی، اغلب نیاز به نوشتن برنامههای کامپیوتری خاصی داشت که کُند و گران بودند.
در نتیجه، بانک دادههای کامپیوتری(Computer Databases) مجزایی شروع به ساخته شدن کردند که بطور خاص برای تأمین کنترل اطلاعات و اهداف آنالیزی طراحی شده بودند.
این انبار دادهها(Data Warehouses) قادر بودند که دادهها را از منابع مختلفی مثل پردازندههای مرکزی (Mainframe Computers) کامپیوترهای کوچک (Mini Computersو همچنین کامپیوترهای شخصی(PC) و نرمافزارهای اتوماتیک اداری مثل برگه گسترده (spread sheet) گرد هم آورند و این دادهها را در یک محل واحد جمع کنند.
این توانایی به همراه ابزارهای گزارشدهی با شیوهی استفادهی آسان(User-friendly) و جدا بودن از اثرات اجرایی، منجر به رشد و توسعهی این نوع از سیستمهای کامپیوتری شد.
همچنان که تکنولوژی پیشرفت کرد (هزینههای کمتر برای عملکرد بهتر)(Lower cost for more performance) و تقاضای کاربران افزایش یافت (سیکلهای زمانی بارگذاری سریعتر و مشخصات بیشتر)(Faster data load cycle times and more features)، انبار داده (Data Warehouses)با عبور از چندین مرحلهی اساسی، تحول یافتند:
۱)Off line Operational Databases
در این مرحلهی اولیه، انبار داده(Data Warehouse) به سادگی با کپی کردن بانک داده(Database) از یک سیستم اجرایی به یک (Off line Server) که در آنجا بار فرایند گزارش، روی اجرا و عملکرد سیستم اجرایی اثر نمیگذاشت، ایجاد میشدند.
۲)Off line Data Warehouse
در این مرحله از تکامل، انبار دادهها(Data Warehouses) طی یک دورهی زمانی منظم (معمولاً روزانه، هفتگی یا ماهانه) از روی سیستمهای اجرایی، به روزسازی(Update) میشدند و داده، با یک ساختار منسجم و مناسب جهتِ گزارش دهی ذخیره میشدند.
۳)Real Time Data Warehouse
در این مرحله، انبار داده(Data Warehouse) بر اساس یک تبادل(Transaction) و یا رویداد(Event Base) به روزسازی (Update)میشوند یعنی هر زمانی که یک سیستم اجرایی، یک تبادل (Transaction)انجام میدهد (مثل یک سفارش یا یک تحویل یا یک ثبت اطلاعات بیماری و ...)
۴)Integrated Data Warehouse
در این مرحله، انبار داده برای ایجاد تبادلات (Transactions) یا فعالیتهایی به کار میروند که برای استفاده در فعالیتهای روزانهی سازمان، به سیستمهای اجرایی(Operational Systems) بازگردانده میشوند.
● ARCHITECTURE (معماری یا ساختار)
مفهومِ «انبار داده»(Data Warehouse) حداقل به اواسط دههی ۸۰ و حتی قبلتر بر میگردد. اصولاً این انبارها به منظور تأمین یک مدل ساختاری(Architectural Model) برای جریان دادهها از سیستمهای اجرایی (Operational Systems)به شرایط پشتیبانی از تصمیمها(Decision Support) ساخته شده بودند و تلاش می شد که مشکلات مختلفی را که در رابطه با این جریان داده(Data) بود و نیز هزینههای سنگین مرتبط با آن را، مخاطب قرار دهد.
در شرایط عدم وجود چنین ساختاری، اغلب مقدار زیادی دادههای زاید در تحویلِ اطلاعات مدیریتی وجود داشت.
در شرکتهای بزرگتر،رسم بر آن بود که برای پروژههایی با پشتیبان تصمیم گیری متعدد(Multiple Decision Support Projects)انبار داده ها (Data Warehouses) بصورت مستقل عمل کنند و هریک به کاربران متفاوتی ارائه خدمات کند اما اغلب مقدار زیادی از دادههایی مورد نیاز ، مشابه بود.
فرایند جمعآوری، پاک سازی و منسجم کردن دادهها از منابع مختلف ( اغلب سیستمهای بازمانده)(Legacy Systems)، برای هر پروژه تکرار میشد. علاوه بر این، هنگامی که یک تقاضای جدید مطرح میشد، سیستمهای بازمانده(Legacy Systems) به وفور مجدداً بازبینی میشدند که هریک نیاز به یک نمای متفاوت از دادههای بازمانده داشتند.
بر اساس شباهتهای موجود با انبارهای واقعی در زندگی معمول، انبار داده(Data Warehouse) به عنوان نواحی جمعآوری/ذخیرهسازی و مرحله بندی در مقیاس وسیع برای ثبت دادهها شناخته میشوند.
از اینجا میتوان دادهها را در «انبارهای کوچکتر»(Retail Stores) یا «بازارهای داده»(Data Mart) پخش کرد که برای دسترسی توسط کاربران پشتیبانی تصمیمگیری (یا مصرف کنندگان)فراهم و مناسب شدهاند.
زمانی که انبار داده(Data Warehouse) به منظور کنترل حجم دادهها از ارائه کنندگان آنها (مثلاً سیستمهای اجرایی) و کمک به سازماندهی و ذخیرهسازی این دادهها طراحی شدند، «بازارهای داده» یا «انبارهای کوچک» روی بستهبندی(Packaging) و ارائه دادهها به کاربران نهایی(End-users) متمرکز شدهاند تا احتیاجات خاص اطلاعات مدیریتی را برآورده سازند.
جایی در طول سیر ساختاری (Data Warehousing)، این دیدِ مقایسهای و (Architectural Vision) از بین رفته است . چون برخی فروشندگان و سخنگویان صنعت، انبار داده را بعنوان یک database گزارشی ساده مدیریتی تعریف کردهاند. که البته این مسئله یک انحراف معیار مبهم اما بسیار مهم از نسخهی اصلی انبار دادهها بعنوان مرکز ساختاری اطلاعات مدیریتی است که در آن سیستمهای پشتیبانی تصمیم(DSS) حقیقتاً «بازارهای داده» و یا «انبارهای کوچکتر» هستند.
▪ OLTP & OLAP
در اینجا لازم است قبل ادامه و شروع مبحث ذخیره(Storage) در مورد این دو اصطلاح توضیح مختصری ارائه شود .
OLTP(Online Transaction Processing)/ در اصل اشاره به گروهی از سیستمها است که Transaction-oriented application را تسهیل و مدیریت میکنند بخصوص در موارد Data entry و Retrieval Transaction processing .
بطور کلی OLTP بهProcessing هایی اطلاق میشود که سیستم در پاسخ های سریع خود به درخواست های کاربر انجام می دهد .
این تکنولوژی در زمینه های بسیاری از جمله E-Commerce E-Banking ,E-Health کاربرد دارد.
OLAP(Online Analitycal Processing)/ یک رویکرد برای بدست آوردن پاسخ های سریع سیستم ها در Analitycal queries که بصورت Multidimensional هستند میباشد.
OLAP بخشی از Business Intelligence بوده که خود شامل مواردی همچون ETI (Extract Transform Load ) و Relational Reporting و Data Mining میباشد.
از کاربرد های رایج OLAP استفاده در گزارش گیری ها مثلBPM (Business Process Management)و بودجه بندی ها (Budgeting) و پیش بینی های مالی است .
خروجی اصلی OLAP QUERY بطور معمول در یک ماتریکس نمایش داده میشود و از تغییر جزئی در همان واژه OLTP اقتباس شده است .
● STORAGE
در بحث ذخیره سازی OLTP در طراحی بانک دادههای ارتباطی از قاعدهی مدلسازی دادهها(Data Modeling) استفاده میکنند و عموماً قواعد Codd را برای نرمال سازی دادهها(Data Normalization) به منظور اطمینان حاصل کردن از انسجام کامل دادهها به کار میبرند.
اطلاعاتی که پیچیدگی کمتری دارند به سادهترین ساختارهای خود شکسته میشوند (در یک جدول) که در آن هر سطح جزئی و کوچک با یکدیگر در ارتباط هستند و از قواعد نرمال سازی پیروی میکنند.
Codd ۵ قاعده مستقیم برای نرمال سازی تعیین میکند و بطور معمول سیستمهای OLTP، یک نرمالسازی درجه ی ۳ دریافت میکنند.
طراحیهای بانک دادهی OLTP با حداکثر نرمالسازی، اغلب منجر به این میشود که اطلاعات ناشی از یک تبادل(Transaction) تجاری در ده ها تاصدها جدول ذخیره شود. مدیران بانک دادههای ارتباطی(Relational Database Managers) در کنترل رابطهی بین جداول و نتایج با اجرای یک Insert/Update سریع ، بسیار کارا عمل میکنند چون مقدار کمی از دادهها در هر تبادل ارتباطی(Relational Transaction)، تحت تأثیر قرار میگیرد.
بانک دادههای OLTP بسیار کارا هستند چون آنها اصولاً فقط با اطلاعات حول و حوش یک تبادل(Transaction) واحد سروکار دارند. در گزارش و آنالیز، هزاران تا بیلیونهاTransaction ممکن است احتیاج به جمعآوری مجدد داشته باشند که سبب تحمیل یک بار کاری عظیم به بانک دادههای ارتباطی میشود.
با دادن زمان کافی، نرمافزار معمولاً میتواند نتایج دلخواه را پس بدهد، اما بعلت اثر منفی رول اجرایی ماشین و همهی تقاضاهایش، متخصصین انبار داده(Data Warehousing)، پیشنهاد میکنند که بانک دادههای گزارش دهنده(Reporting Databases) به صورت فیزیکی ازOLTP Database جدا شوند.
علاوه بر این،نبار سازی دادهها Data Warehousing پیشنهاد میکند که بهتر است داده ها (Data) به منظور تسهیل مقایسه و آنالیز توسط کاربران تازهکار، بازسازی و مجدداً مرتب شوند.
بانک دادههای OLTP برای تأمین یک عملکرد خوب در پاسخ به درخواستهای دقیق، توسط برنامهریزیهای ماهر در زمنیهی محدودیتها و آداب و رسوم تکنولوژی طراحی شدهاند.
علاوه بر تقویتهای بسیار، یک بانک داده(Database) هنوز فقط یک مجموعه از نامهای مبهم و نامربوط به نظر میرسد و دارای ساختار غیر قابل درکی است که با استفاده از کدهای نامفهوم، داده(Data) را ذخیره میکنند. و اینها همه فاکتورهایی است که ضمن بهبود عملکرد، سبب پیچیده شدن استفاده توسط افراد آموزش ندیده میشود.
در نهایت، انبار دادهها(Data Warehouses) نیاز به تأمین حجمهای بالایی از دادههای گردآوری شده از میان دورههای وسیعی از زمان دارند و در معرض مقایسات پیچیده قرار دارند وضمنا به فرمتهای متعدد و توضیحات بر گرفته شده از سیستمهای بسته بندی(Package) و بازمانده(Legacy Systems) که به طور مستقل طراحی شده، نیاز دارند.
طراحی انبار داده(Data warehouse) به صورت همزمان با ساختمان داده(Data Architecture)، هدف آرشیتکتهای انبارهای داده است.
هدف اصلی(Goal Target) یک انبار داده(Data Warehouse)، گرد هم آوردن دادهها از انواعی از بانک دادههای(Databases) موجود برای تأمین نیازهای گزارشدهی و مدیریتی است.
اصل پذیرفته شدهی کلی این است که دادهها باید تا سطوح بسیار اولیهشان(Elemental Level) ذخیره شوند چون این کار، انعطافپذیرترین و مفیدترین پایه را برای استفاده در آنالیز و گزارش اطلاعات فراهم میکند.
با این وجود، بعلت توجههای مختلف روی نیازهای خاص، روشهای جایگزینی هم میتواند برای طراحی و اجرای انبارهای داده بکار رود.
۲ رویکرد اصلی برای سازماندهی دادهها در یک انبار داده وجود دارد:
۱) رویکرد ابعادی (Dimensional Approach) که توسط Ralph Kimball مطرح شده است و
۲) رویکرد نرمالیزه شده(Normalization Approach) که توسط Bill Inmon مطرح شده است.
در حالیکه رویکرد ابعادی(Dimensional Approach) در طراحی بازار دادهها(Data Mart Design) بسیار مفید است، میتواند منجر به انبوهی از الحاقات دادهای طولانی مدت و عوارض پیچیدهای در صورت استفاده از آن در یک انبار داده شود.
در رویکرد ابعادی(Dimensional Approach) ، دادههای تبادلات (Transaction Data) به وقایع(Fact) قابل اندازهگیری که عمدتاً دادههای عددی هستند و مقدارهای خاصی دارند و یا به «ابعادی»(Dimensional که حاوی اطلاعات مرجع(Reference) هستند که محتوای هر Transaction را تعیین میکنند،تقسیم می شوند.. بعنوان مثال، یک معاملهی فروش به وقایعی(Facts) مثل تعداد محصولات سفارش داده شده و یا قیمت پرداخت شده تقسیم شود و یا به ابعادی(Dimension) مثل تاریخ، خریدار، محصولات و موقعیت جغرافیایی و فروشنده تقسیم شود.
از مزایای اصلی(Main Advantages) یک رویکرد ابعادی (Dimensional Approach) این است که انبار داده(Data Warehouse) برای کارکنانی که در زمینهی (IT) تجربیات کمتری دارند، به لحاظ درک و کاربرد راحتتر است. همچنین، چون دادهها بصورت ابعادی(Dimensional بهم متصل هستند، انبار داده بسیار سریع عمل میکند.
نکتهی منفی اصلی (Main Disadvantage) در رویکرد ابعادی(Dimensional این است که اضافه کردن یا تغییرات بعدی در صورتی که شرکت رویه ی خود را در تجارت تغییر دهد، مشکل خواهد بود.
در رویکرد نرمالیزه شده(Normalization Approach) از نرمال سازی بانک داده(Database Normalization) استفاده میشود. در این روش، دادهها در انبار داده به شکل سومِ نرمال(Third Normal Form) ذخیره میشوند. سپس جداول توسط Subject Area گرد همآوری میشوند که منعکس کنندهی تعریف کلی داده(Data) هستند،مثل (خریدار، محصول، اعتبارات و ...).
مزیت اصلی این رویکرد این است که برای اضافه کردن اطلاعات جدید به بانک داده(Database) تقریباً مستقیم(Straightforward) عمل میکند
و نکتهی منفی اولیه در رابطه با آن این است که بعلت تعدد جدولهای درگیر، تولید اطلاعات و گزارشها، ممکن است نسبتاً آهسته باشد.
علاوه بر این، از آنجایی که جداسازی وقایع(Facts) و ابعاد(Dimensions) در این نوع از مدل دادهها(Data Model)، روشن نیست، برای کاربران مشکل است که اجزای دادههای مورد نیاز را به هم بپیوندند و اطلاعات معنیداری بدون درک ساختار دادهها پیدا کنند.
Subject Areas، فقط روشی برای سازماندهی اطلاعات هستند و میتوانند در طول هر خطی تعریف شوند.
● ADVANTAGES
بطور کلی مزایای بسیاری در استفاده از یک انبار داده (Data Warehouse)وجود دارد، که برخی از آنها شامل:
۱)دسترسی کاربران نهایی(End-Use Access) را به طیف متنوعی و وسیعی از دادهها میسر میکند.
۲)کاربران سیستمهای پشتیبانی تصمیم (DSS Users) میتوانند گزارشات خاصی را بدست آورند یعنی مثلاً کالایی که بیشترین فروش را در یک منطقه/کشور خاص در طول ۲ سال گذشته داشته است.
۳)یک انبار داده(Data Warehouse) میتواند یک وسیلهی مهم در درخواستهای تجاری باشد بخصوص مدیریت ارتباط با خریدار،CRM(Customer Relationship Management)
● CONCERNS
از نکات مهمی که در این زمینه وجود دارد می توان به موارد ذیل اشاره کرد:
۱)استخراج، جابجایی و بار کردن دادهها(Loading)، زمان زیادی میبرد و منابع کامپیوتری زیادی نیاز دارد.
۲)گسترهی پروژه ای انبار دادهها((Data Warehouse باید بطور فعال کنترل شود تا مجموعهای از مقادیر و محتویات تعریف شده ارائه گردد.
۳)مشکلات مربوط به سازگاری با سیستمهای قبلی موضوع قابل اهمییتی است.
۴)امنیت(Security) میتواند تبدیل به موضوعی جدی شود، بخصوص اگر انبار داده توسط web قابل دسترسی باشد.
۵)اختلاف نظرهای موجود دربارهی طراحی دخیرهسازی دادهها (Data Storage Design)مستوجب ملاحظات دقیقی میباشد و نیز شاید پیشسازی راه حلهای انبارهای داده (Data Warehouses)را برای شرایط هر پروژه، ایجاب کند.
گرد آورنده:دکتر حسین مجاهدی
کارشناس ارشد مدیریت فناوری اطلاعات پزشکی
حسین مجاهدی














































































ایران مسعود پزشکیان دولت چهاردهم پزشکیان مجلس شورای اسلامی محمدرضا عارف دولت مجلس کابینه دولت چهاردهم اسماعیل هنیه کابینه پزشکیان محمدجواد ظریف
پیاده روی اربعین تهران عراق پلیس تصادف هواشناسی شهرداری تهران سرقت بازنشستگان قتل آموزش و پرورش دستگیری
ایران خودرو خودرو وام قیمت طلا قیمت دلار قیمت خودرو بانک مرکزی برق بازار خودرو بورس بازار سرمایه قیمت سکه
میراث فرهنگی میدان آزادی سینما رهبر انقلاب بیتا فرهی وزارت فرهنگ و ارشاد اسلامی سینمای ایران تلویزیون کتاب تئاتر موسیقی
وزارت علوم تحقیقات و فناوری آزمون
رژیم صهیونیستی غزه روسیه حماس آمریکا فلسطین جنگ غزه اوکراین حزب الله لبنان دونالد ترامپ طوفان الاقصی ترکیه
پرسپولیس فوتبال ذوب آهن لیگ برتر استقلال لیگ برتر ایران المپیک المپیک 2024 پاریس رئال مادرید لیگ برتر فوتبال ایران مهدی تاج باشگاه پرسپولیس
هوش مصنوعی فناوری سامسونگ ایلان ماسک گوگل تلگرام گوشی ستار هاشمی مریخ روزنامه
فشار خون آلزایمر رژیم غذایی مغز دیابت چاقی افسردگی سلامت پوست