جمعه, ۲۱ دی, ۱۴۰۳ / 10 January, 2025
روشی برای رفع چالش های محتواكاوی وب های فارسی زبان
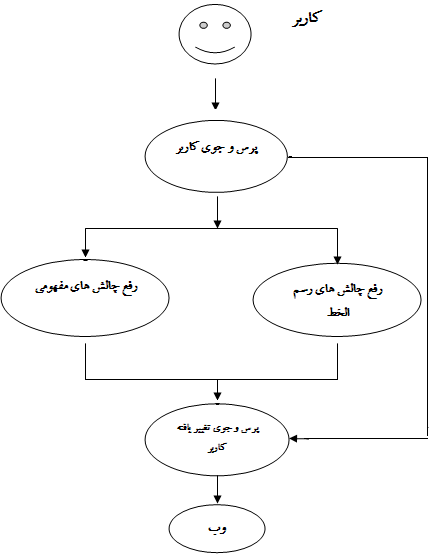
رشد علمی و فنی و فرهنگی ما در گرو برقراری ارتباط زبانی و كلامی با دنیای الكترونیكی عرضه دانش و فرهنگ است كه وب نام دارد و این میسر نیست جز با تقویت كیفی زبان فارسی مورد استفاده در این دهكده جهانی ، وب.لیكن زبان فارسی ، در تلاقی با جهان الكترونیكی ، بخصوص از بعد رسم الخط ، دارای مصائبی است كه كاوش در محتویات آن را دچار كم كیفیتی می نماید. این مقوله مستلزم تمهیداتی چند است تا زبان فارسی را از یك زبان شعر وعرفان به زبانی مناسب با پهنه الكترونیكی دادوستد دانش ، وب ، تبدیل نمایند. مقاله حاضر ، تلاشی است درجهت مرتفع سازی چالش های كاوش در وب های فارسی زبان كه از دو دیدگاه رسم الخط ، با استفاده از نمایه سازی فارسی و مفهومی ، با استفاده از آنتولوژی قابل بحث هستند.
واژه های كلیدی : آنتولوژی ، نمایه سازی فارسی ، كاوش وب های فارسی ، وب كاوی
مقدمه
اهمیتی كه پدیده وب فارسی بعنوان رسانهای مستقل و مؤثر در دنیای ارتباطات ایرانیان پیدا كرده است ، غیرقابلانكار است. بهنظر میرسد كه اكنون روآوردن برخی از روزنامهنگاران ، پژوهشگران ، دانشجویان ،... به وب فارسی و استفاده منابع خبری ، علمی ،... از مطالب آنها نیز، موجب تقویت نقش رسانهای وب فارسی شدهاست.
لیكن با توجه به ماهیت خاص رسم الخط فارسی كه آن را برای سیستم های رایانه ای نامناسب نموده است ، امروزه مشكلات بسیاری برای دانش پژوهشان و بطور كلی استفاده كنندگان از وب های فارسی زبان نموده است. عدم وجود حروف صدادار در فارسی بصورت یك موجودیت مجزا از یك طرف و وجود حروف یكسان با اشكال متعدد از طرف دیگر ، باعث بروز چالش های جدی در امر نمایه سازی این زبان شده است. بنظر می رسد تلاشهایی لازم است تا زبان زیبای فارسی را با وجود ماهیت عرفانی و شاعرانه آن ، جهت حضور در عرصه الكترونیكی دانش ، آماده نماید.
پیشینه تحقیق و تعارف ابتدایی
محتواكاوی وب(Web Content Mining) ، یكی از سه شاخه وب كاوی است كه در واقع ، كشف اطلاعات مفید از مستندات و داده های ساختیافته و نیمه ساختیافته و غیر ساختیافته وب می باشد. یك شاخه دیگر این مقوله ، ساختاركاوی وب(Web Structure Mining) است كه به كشف مدل پشت زمینه حاكم بر ساختار فرا پیوند های وب می پردازد و هدف آن ، ایجاد اطلاعاتی همچون تشابه یا ارتباط بین سایت های مختلف وب است. شاخه دیگر آن كاربرد كاوی وب می باشد كه سعی می كند از تعاملات كاربربا وب ، اطلاعاتی كسب كند و از آن ها بصورت سابقه ای در مراجعات بعدی كاربر سود ببرد.در زمینه محتواكاوی وب نرم افزارهای خزنده(Crawler) ، به گشت و گذار در اقیانوس وب پرداخته ، اقدام به نمایه سازی واژگان در پایگاه داده خود می نمایند كه مورد استفاده موتورهای كاوش ، در زمان جستجوهای كاربر قرار می گیرد. نمونه بارز این روش ، موتور كاوشگر Google است. .[Chakrabarti,۱۹۹۹]در همین راستا ابزارهایی همچون FASTUS:Finite-State Automaton Text Understanding System ، در خلال این ماموریت به تجزیه و تحلیل متون ، با هدف كشف گروه های مختلف واژگان مانند اسامی ، افعال ، تركیبات وصفی و اضافی ،... می پردازند كه به كشف دانش از محتویات وب كمك می كند. این روش هم اكنون برای زبان های انگلیسی و ژاپنی پیاده سازی شده است وبصورت بالقوه برای دیگر زبان ها قابل استفاده است. [Feiyu,۲۰۰۱]
از طرف دیگر استفاده از آنتولوژی(Ontology) در وب در بهینه سازی كاوش در وب پیشنهاد می گردد. آنتولوژی ، یك فرهنگ واژگان مشترك بر اساس موضوع سایت برای استاندارد سازی ارائه مفاهیم آن جهت قابل تفسیر شدن توسط ماشین ، تعریف می كند. آنتولوژی ، یك جزء كلیدی وب مفهومی(Semantic Web) است. [Heflin,۲۰۰۰]
شخصی كردن وب(Personalization) ، از دیگر روش هاست كه در امر كاوش وب مثمر ثمر است. نمونه این روش در My Yahoo قابل مشاهده است.یكی دیگر از راه های كاوش در مقدار زیاد و غیر ساختیافته اطلاعات وب ، استفاده از پایگاه داده چند لایه ای (MLDB) است. هر لایه از این پایگاه داده ، تعمیم بیشتری از لایه قبلی است. همه لایه ها بجز پایین ترین لایه (كه خود وب است) ، قابل كاوش توسط یك زبان پرس وجو مثل SQL است. [Osmar,۲۰۰۲]
در پیاده سازی روش های ساختاركاوی وب ، از تئوری گراف وب بهره مند خواهیم شد كه به ایجاد دید ارزشمند در الگوریتم های جستجو ، كشف ارتباطات ،... موثر است.در خصوص روش های كاربرد كاوی وب ، ناوبری كاربر در وب توسط مدل های ریاضی ماركو(Markov) ، براساس میزان تجربه كاربر و دارا بودن یا عدم داشتن راهنمای سایت ، تجزیه و تحلیل می گردد. [Velasquez,۲۰۰۳]خصوصیات وب های فارسی از نظر زبان
عدم وجود یك استاندارد و شناور بودن ویژگیهای رسم الخط و مفاهیم در زبان فارسی ، موجب گردیده است تا تقریبا بتعداد صفحات وب فارسی ، سبك و سیاق نگارش این زبان بكار رفته باشد. لیكن خصوصیات مشترك اكثر وبهای فارسی زبان را می توان چنین ارزیابی نمود :
الف) نگارش برخی از وب های فارسی ، زبان غیررسمی یا محاورهای است.
ب) در وبهای فارسی ، بخصوص در متون علمی ، اغلب واژههای بیگانه ، بكرات استفاده میشود كه بعضی از آنها بارسم الخط زبان اصلی نوشته میشوند.
ج) رسمالخط وب های فارسی ، اصولا غیراستاندارد و متغیر است و اغلب در معرض نوآوری است.
ه) نوشتههای وبهای فارسی ، حاوی غلطهای تایپی و نگارشی نسبتاً زیادی است، هرچند كه اغلب وبهای فارسی مهم و پرخواننده، نگارش قابلقبولی دارند.
و) رسمالخط وبهای فارسی، تابع محدودیتهای محیط الكترونیكی و عدم تطبیق آن با الزامات خط فارسی است.]اشرف زاده،۱۳۸۳[ابزارهای جستجو در وب های فارسی














































































ایران مسعود پزشکیان دولت چهاردهم پزشکیان مجلس شورای اسلامی محمدرضا عارف دولت مجلس کابینه دولت چهاردهم اسماعیل هنیه کابینه پزشکیان محمدجواد ظریف
پیاده روی اربعین تهران عراق پلیس تصادف هواشناسی شهرداری تهران سرقت بازنشستگان قتل آموزش و پرورش دستگیری
ایران خودرو خودرو وام قیمت طلا قیمت دلار قیمت خودرو بانک مرکزی برق بازار خودرو بورس بازار سرمایه قیمت سکه
میراث فرهنگی میدان آزادی سینما رهبر انقلاب بیتا فرهی وزارت فرهنگ و ارشاد اسلامی سینمای ایران تلویزیون کتاب تئاتر موسیقی
وزارت علوم تحقیقات و فناوری آزمون
رژیم صهیونیستی غزه روسیه حماس آمریکا فلسطین جنگ غزه اوکراین حزب الله لبنان دونالد ترامپ طوفان الاقصی ترکیه
پرسپولیس فوتبال ذوب آهن لیگ برتر استقلال لیگ برتر ایران المپیک المپیک 2024 پاریس رئال مادرید لیگ برتر فوتبال ایران مهدی تاج باشگاه پرسپولیس
هوش مصنوعی فناوری سامسونگ ایلان ماسک گوگل تلگرام گوشی ستار هاشمی مریخ روزنامه
فشار خون آلزایمر رژیم غذایی مغز دیابت چاقی افسردگی سلامت پوست